[캐글_kaggle] 필사하기 (1)
캐글 코리아 의 '그랜드 마스터' 님이신 이유한 님의 '캐글 입문' 커리큘럼을 보고, 필사를 다짐!
1. DieTanic 데이터셋을 이용해서 생존자 예측하기
2. 데이터셋 설명

3. 본격 필사하기
[1] EDA
import numpy as np
import panda as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirytyeight')
import warnings
warnings.fulterwarnings('ignore')
%matplotlib inline
- plt.style.use('fivethirtyeight')
-> 역할: matplotlib의 그래프 스타일을 'fivethirtyeight'로 변경
- import warnings
-> 역할: python의 경고 메시지를 제어하기 위한 'warnings'모듈을 불러옴
-> tjfaud: 코드 실행 중에 발생할 수 있는 경고 메시지를 처리하거나 무시할 수 있게 해줌 (경고를 출력하거나, 특정 경고를 무시하거나, 경고를 오류처럼 처리할 수 있음)
- warnings.filterwarnings('ignore')
-> 역할: 모든 경고 메시지를 무시하도록 함
-> 설명: 이는 분석 중에 중요한 오류가 아니라고 판단되는 경고를 숨길 때 유용함
- %matplotlib inline
-> 역할: 주피터 노트북에서 그래프를 '인라인(노트북 셀 안)'에서 바로 출력할 수 있도록 설정함
-> 설명: matplotlib을 사용하는 경우, 그래프를 별도의 창이 아닌 '주피터 노트북 셀 내부에 표시'되도록 함/
즉, 시각화가 셀 아래에 바로 출력되며, 노트북을 실행할 떄마다 그래프가 자동으로 표시됨
data= pd.read_csv('../input/train.csv')
data.head()

data.isnull().sum() #데이터셋 내 결측치 갯수 확인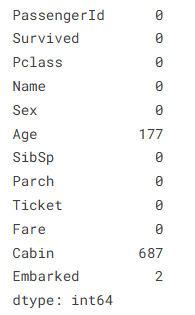
f.ax= plt.subplots(1,2,figsixe=(18,8))
data['Surived'].value_counts().plot.pie(explode=[0,0,1],autopct='%1.1f%', ax=ax[0], shadow= True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived', data=data, ax=ax[1])
ax[1].set_title('Survived')
plt.show()
- f,ax = plt.subplots(1, 2, figsize=(18,8))
-> 역할: 한 줄에 2개의 그래프를 그리기 위한 Figure와 Axes 객체를 생성함 (행, 열= 1, 2)
-> 설명: 'plt.subplots(1,2)는 1행 2열의 레이아웃 생성/ figsize=(18,8)은 전체 그래프의 크기를 지정하는 것
-> f (Figure 객체)와 ax(Axes 객체 리스트를 반환)


- data['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax= ax[0], shadow= True)
-> 역할: data['Survived'] 컬럼의 생존 여부에 대한 파이 차트 그리기
-> 설명:
- data['Survived'].value_counts() 는 Survived 열의 값 개수를 계산
- plot.pie() 는 이 데이터를 사용하여 파이 차트를 그림 -> Survived 가 0 (생존하지 않음), 1 (생존함) 이면 그것에 대한 파이차트 그리기
* explode= [0, 0.1] 은 두개의 값 중 두번째 값을 약간 '튀어나오게 설정하여 차트에서 강종하는 효과
* autopct= '%1.1f%%'는 파이 차트 내에서 백분율을 소수점 첫째 자리까지 표시하도록 함
* ax= ax[0] 은 위에서 생성한 1행 2열의 figure 에서, ax=0 (첫 번째 그래프 영역)에 차트를 그리도록 지정함
* shadow= True 는 그림자 효과를 추가하여 차트에 입체감을 줌
파이차트는 '원형 그래프'로, 카테고리별 통계치의 비율을 직관적으로 보고 싶을 때 사용하는 그래프
- 선택인자 explode 는 '각 Pie(항목) 에 따라, 원점에서 튀어나오는 정도를 나타내며, 강조하고 싶을 때 사용)
-> explode =[ 0, 0.1, 0, 0]/ plt.title('Pie chart explode')/ plt.pie(sizes, explode= explode)/ plt.show()
- 선택인자 labels 는 '각 Pie 에 대한 Label 을 인자로 전달하여 어떤 항목을 가리키는지 명시적으로 표시함
-> labels= ['Frogs', 'Dogs', 'Hogs', 'Logs'] / plt.title('Set Labels')/ plt.pie(sizes, explode= explode, labels= labels)/ plt.show()

* 자료출처= https://m.blog.naver.com/xoxo_pch/222706346420
[Python matplotlib] 파이 차트 (Pie Chart) 정리
안녕하세요. 모찌아빠입니다. 오늘은 matplotlib 라이브러리의 파이 차트에 대해 정리하려고 합니다. 파이 ...
blog.naver.com
-> 891명의 훈련 데이터들 중에 [Survived= 1] 에 해당하는 비율은 350명정도, 즉 전체에서 38.4%
생존비율을 다른 피처인 성별, 탑승지 나이 등으로 확인할 것
범주의 유형
- 범주형 변수: 성별과 같이 2개 이상의 범주를 가지는 변수로 각각의 값으로 feature가 카테고리화됨 (예: 성별, Embarked)
- 순서형 변수: 순서형 변수는 말 그대로 순서를 가지는 변수로 설문조사 시 1점, 2점, 3점과 같은 변수 (예: Pclass)
- 연속형 변수: 어떤 변수가 특정 두 지점, 혹은 최댓값과 최솟값 사이에 어떤 값이든 가질 수 있는 변수 (예: Age)
(1) 변수 분석하기 (생존비율 확인) -> 각 변수별로 EDA를 진행
- 성별= 범주형 변수
data.groupby(['Sex', 'Survived'])['Survived'].count()
-> 성별 변수는 범주형 변수로 막대그래프를 이용하여 비교할 수 있다.
f.ax= pl.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived cs Sex')
sns.countplot('Sex', hue='Survived', data=data, ax= ax[1])
ax[1].set_title('Sex: Survived vs Dead')
plt.show()
- f, ax= plt.sibplots(1, 2, figsize=(18,8))
-> 역할: 'f,ax= plt.sibplots ~' 는 옵션이고, 1행 2열의 그래프 그림
-> 설명: Figure 객체 'f'와 각 그래프를 그릴 공간을 나타내는 Axes 객체 리스트 'ax'를 반환함 -> ax[0], ax[1] 그래프
- data[['Sex', 'Survived']].groupby(['Sex']).mean().plot.bar(ax= ax[0])
-> 역할: 성별에 따른 (groupby(['Sex'])) 평균 생존 비율을 막대 그래프로 표시
-> 설명:
- data[['Sex', 'Survived']] 는 'Sex' 와 'Survived' 열만 선택한 새로운 데이터프레임을 만듦
- .goupby(['Sex'])는 성별에 따라 데이터를 그룹화함
- .mean() 은 각 그룹에서 '생존율의 평균을 계산함 -> 남성 그룹의 생존율과 여성 그룹의 생존율을 계산함
- .plot.bar(ax= ax[0]) 은 이 데이터를 '막대 그래프'로 그리고, ax[0] 에 표시
* '성별'을 기준으로 그룹화한 다음 'Survived'의 평균을 계산하여 '성별에 따른 생존율의 평균'을 그릴 수 있음
- sns.countplot('Sex', hue= 'Survived', ' data=data, ax= ax[1])
-> 역할: 성별에 따른 생존여부 (생존/ 사망)를 비교하는 막대그래프 'countplot'을 그림
-> 설명:
- sns.countplot('Sex', hue= 'Survived', data=datam ax=ax[1]) 는 Seaborn의 countplot() 함수로 '성별에 따른 생존 여부의 분포를 그림
- 'Sex' 는 분석할 카테고리 (성별)를 지정하고, hue='Survived' 는 생존 여부를 다른 색으로 구분하여 '성별에 따른 생존과 사망'을 각각 다른 색으로 나눠 표시함
- data= data 는 데이터프레임을 전달
- ax= ax[1] 은 두 번째 그래프 영역(ax[1])에 이 차트를 그리도록 지정
(오른쪽 시각화를 통해) 배에 타고 있는 사람들의 수는 남자들이 여자들보다 훨씬 많지만 성별에 따른 생존율을 확인해보았을 때 여성은 75%, 남성은 18-19%로 여자들의 생존율이 훨씬 높다는 것을 알 수 있음. 이는 추후 중요한 변수로 사용할 수 있다.
- Pclass (티켓 클래스) = 순서형 변수
pd.crosstab(data.Pclass.data.Survived, margins= True).style.background.gradient(cmap= 'summer_r')

- pd.crosstab(data.Pclass, data.Survived, margins= True)
-> 역할: pd.crosstab() 을 사용하여 'Pclass' (티겟클래스)와 'Survived' (생존 여부)에 대한 교차표 (피벗 테이블)을 생성하고, 그걸 시각화함
-> 설명:
- pd.crosstab() : 두 개의 카테고맇ㅇ 변수 간의 교차표(빈도표)를 생성하는 함수 -> 교차표는 각 카테고리 조합의 빈도 수를 나타냄
- data.Pclass: 첫 번째 변수 -> 티켓 클래스 (Pclass)를 기준으로 그룹화함
- data.Survived: 두 번째 변수 -> 생존여부 (Survived)를 기준으로 그룹화함
- margins= True: 교차표에 행과 열의 합계 (총계)를 추가함 -> 각 클래스와 생존 여부에 대한 빈도뿐 아니라, 모든 클래스와 모든 생존 여부에 대한 전체 합계를 볼 수 있음
.style.background_gradient(cmap='summer_r')
-> 역할: '.style.baclground_gradient()' 은 생성된 교차표에 색상 그라데이션을 추갛ㅏ여 데이터 값을 시각적으로 강조하는 기능
-> 설명:
- cmap='summer_r' 은 '색상 맵(color map)'을 설정하여, 'summer_r' 이라는 역방향 여름 테마 색상을 사용함
- '색상 맵'은 표의 각 값에 대해 '값의 크기에 따라 색상'을 적용하는 방식으로 값이 클수록 더 짙은 색으로 표현됨
- summer_r 은 밝은 노락색에서 초록색으로 변하는 색상 맵, '_r'은 reverse(역방향) 를 의미하여 색상이 반대로 적용
재구조화 (reshaping data)를 위해 사용할 수 있는 함수
-> pivot() -> pd,pivot_table()
-> stack(), unstack()
-> melt()
-> pd.crosstab()
pd.crosstab(index, columns)
-> pd.crosstab(data.Pcalss, data.Survived, margins=True)
-> 행: data.Pclass/ 열: data.Survived
-> 'margins= True' 은 각각에 대한 행 합과 열 합 추가하기
* Multi-index를 위해선 pd.crosstab([id1,id2], [col1,co2])
* 구성비율로 교차표 만들기: pd.crosstab(normalize= True)
f,ax= plt.sunplots(1,2, figsize=(18,8))
data['Pclass'].value_counts().plot.bar(color=[''#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0])
ax[0].set_title('Number of Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass', hue='Survived', data=datam ax=ax[1])
ax[1].set_title('Pclass:Survived vs Dead')
plt.show()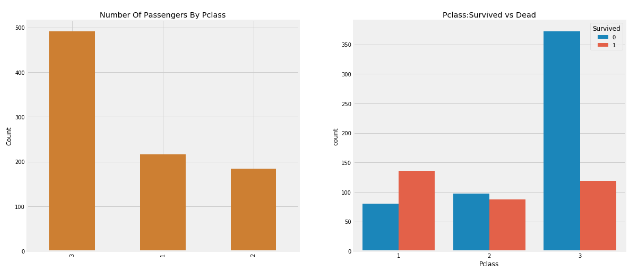
- 성별과 '티켓 클래스'를 함께 본다면?
pd.crosstab([data.Sex, data.Survived], data.Pclass, margins=True).style.backgournd_gradient(cmap='summer_r')# 행은 멀티로 'data.Sex', 'data.Survived' 이고, 열에는 'data.Pclass'가 있음

sns.factorplot('Pclass', 'Survived', hue='Sex', data=data)
plt.show()
sns.factorplot()
-> 역할: '.style.baclground_gradient()' 은 생성된 교차표에 색상 그라데이션을 추갛ㅏ여 데이터 값을 시각적으로 강조하는 기능
-> 설명:
- factorplot() 은 Seaborn 에서 범주형 데이터를 시각화하는 함수, 기본적으로 막대 그래프, 포인트 플롯, 박스 플롯 등의 다양한 그래프를 그릴 수 있으며, 범주형 변수의 관계를 시각화할 때 자주 사용됨
* sns/catplot() 으로 대체됨 -> sns.catplot()
Pclass (첫 번째 인수)
-> 설명: X 축에 표시될 '범주형 변수'를 지정함 -> Pclass (티켓 클래스)를 기준으로 각 범주 (1, 2, 3 등급)을 시각화함
Survived (두 번째 인수)
-> 설명: Y축에 표시될 '숫자형 변수'를 지정함 -> Survived (생존 여부, 0: 사망함, 1:생존함)
-> X 축 (티켓 클래스) 에 대한 생존율 (평균 생존 비율)이 Y축 에 나타남
hue= 'Sex'
-> 설명: '성별'을 기준으로 다른 색상으로 데이터를 나누어 비교함
-> hue 는 데이터를 색깔별로 나누는 인수/ 남성 (Male)과 여성 (Female)에 따라 생존율이 달라질 수 있으므로, 그래프에서 성별에 따른 차이를 시각화함 (남성과 여성을 다른 색으로 구분하여 표시함)
data= data
-> 분석할 데이터프레임을 지정함/ data는 '분석에 사용할 데이터셋'

PClass가 1인 사람들 중 여성은 3명이 죽고 91명이 살았지만 (95-96%) 전체적으로 Pclass에 상관없이 여성은 우선적으로 생존의 기회가 주어졌다. -> Pclass가 중요한 변수임을 알 수 있음
- 나이= 연속형 변수
print('Oldest Passenger was of:', data['Age'].max(). 'Years')
print('Youngest Passenger was of:', data['Age'].min(), 'Years')
print('Average Age on the ship:', data['Age'].mean(), 'Years')
-> 바이올린 플롯은 각 class별 전체적인 분포를 비교하는데 좋은 시각화
f.ax= plt.subplots(1,2, figsize= (18,8))
sns.viloinplot('Pclass', 'Age', hue='Survived', data=data, split= True, ax= ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex', 'Age', hue= 'survived', data=data, split=True, ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()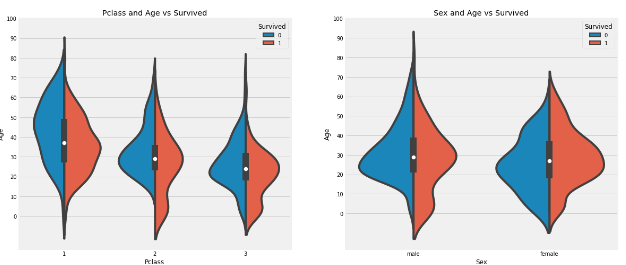
- sns.violinplot('Pclass', 'Age', hue= 'Survived', data=data, split= True, ax= ax[0])
-> 역할: sns.violinplot() 은 'Violin plot' 을 그리는 Seabron 함수 -> Violin plot은 데이터의 분포를 커널 밀도 추정 (KDE)으로 시각화하며, 박스 풀롯과 KDE 의 결합 형태
-> 설명:
- Pclass: X 축에 표시할 변수 (범주- 순서형)
- Age: Y 축에 표시할 연속형 변수
- hue= 'Survived' 은 생존 여부에 따라 '다른 색'으로 나누어 표현함 -> 생존 여부 (0= 사망, 1= 생존)를 기준으로 나이 분포를 두 가지 색으로 나누어 시각화함
- split= True : 하나의 violin 에 두 데이터 (생존/ 사망)를 나눠서 표시함. Violin plot 이 반으로 나뉘며, 한쪽은 생존자 다른 한쪽은 사망자의 나이 분포를 나타냄
- ax=ax[0] : 첫 번째 그래프에 그려짐
- ax[0].set_yticks(range(0, 110, 10)):
-> 설명 : Y 축의 눈금 (ticks)을 0에서 110까지 10 단위로 설정함 (Y 축에 0, 10, 20.. 100 까지의 눈금을 표시함)
- sns.violinplot('Sex', 'Age', hue= 'Survived', data=data, split= True, ax= ax[1])
-> 설명:
- Sex: X 축에 '성별'을 설정함 (범주형 변수)
- Age: Y 축에 '나이'를 설정함 (연속형 변수)
- hue= 'Survived' : 생존 여부에 따라 다른 색으로 나눠 표현함
- split= True : 한쪽은 생존자의 나이 분포, 다른 한쪽은 사망자의 나이 분포를 나타냄
- ax= ax[1]: 두번째 그래프에 그려짐
- ax[0].set_yticks(range(0, 110, 10))
1) ax[0] : '티켓 클래스 (Pclass)'에 따른 나이 (Age) 분포를 보여주며, '생존 여부 (Survived)'에 따라 색깔이 나누어짐
2) ax[1]: '성별 (Sex)'에 따른 나이 (Age) 분포를 보여주며, '생존 여부 (Survived)'에 따라 색깔이 나누어짐
3) Violin plot 은 각 그룹의 나이 분포를 커널 밀도 추정으로 시각화하며, '생존자와 사망자의 나이 분포 차이'를 시각적으로 확인할 수 있음
1) Pclass 등급이 낮아짐에 따라 어린이의 수가 증가한다. 그중 10세 미만의 생존율이 Pclass1을 제외하고는 좋아 보인다.
2) 20-50세 사이의 Pclass1 탑승객 생존율이 높고 여성의 경우 매우 높은 것으로 보인다.
3) 남성은 여성에 비해 나이가 많을수록 더 많이 사망했고 여성은 전체적으로 생존률이 높으나 20대-40대에 생존률이 높다.
나이 변수에 대해서 177개의 결측치가 존재했기 때문에 이 값을 처리할 방안이 필요하다. 문제는 모두가 각기 다른 나이를 가지고 있고, 4살 짜리 어린아이를 29 세의 나이로 대체할 수는 없다.
외국은 Mr, Mrs와 같이 이름 앞에 호칭을 붙인다. 이를 이용하여 결측치를 대체할 것이다.
data.Name[1:5] #data['Name'][1:5]
data['Initial']=0
for i in data:
data['Initial']= data.Name.str.extract('([A-Za-z]+)\.')
- data['Initial']= 0
-> 역할: 'Initial' 이라는 새로운 열을 만들고, 그 열의 모든 값을 0으로 초기화함 (다른 값들을 추가하거나 수정하기 위한 준비 단계, Initial 얄 에 데이터를 저장할 공간을 만듦)
- data['Initial']= data.Name.str.extract('([A-Za-z] + )\.')
-> 역할: Name 열에서 특정 패턴을 찾아 'Initial' 열에 저장하는 작업
-> 설명 : 'str.extract('([A-Za-z]+)\.')' 은 이름에서 '알파벳 문자열 (A-Za-z)' 로 시작하고, '.' (점)으로 끝나는 '타이틀 (Mr, Mrs, Dr. 등)'을 추출하는 역할
- 승객의 이름에서 'Mr. , Mrs. , Miss. ' 등과 같은 타이틀을 추출하여 'Initial'열에 저장하는 것

pd.crosstab(data.Initial, data.Sex).T.style.background_gradient(cmap='summer_r')
- .T
-> 역할: 데이터 프레임의 전치 (transpose)를 수행함 즉 행과 열을 서로 바꾸는 작업을 수행
-> 설명 : 원래 교차표에선 'data.Initial' 이 행 인덱스가 되고, 'data.Sex' 가 열 인덱스가 되지만, 전치 후엔 'data.Sex' 가 행 인덱스가 되고, 'data.Initial' 이 열 인덱스가 됨
- .style.background_gradient(cmap= 'summer_r') :
-> 설명 :
- '.style' 속성은 pandas 데이터 프레임에 스타일을 적용할 수 있는 방법을 제공함
- '.background_gradient' 메서드는 셀 배경 색상을 gradient (그라디언트) 색상으로 채우는 기능을 함
- cmap= 'summer_r' 은 그라디언트 색상을 여름 색상 맵을 역순으로 사용하겠다는 의미. 즉, 낮은 값은 연한 색으로, 높은 값은 진한 색으로 표시
자료출처: 캐글
https://www.kaggle.com/code/isaaclys/eda-to-prediction-dietanic-korean-translation
EDA To Prediction (DieTanic) korean translation
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
https://www.kaggle.com/code/alexisbcook/titanic-tutorial
Titanic Tutorial
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
EDA To Prediction(DieTanic) (kaggle.com)
EDA To Prediction(DieTanic)
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
https://ssung-22.tistory.com/m/72
[Kaggle 필사] DieTanic 데이터로 EDA 필사하기!!
지난 2020년 10월 한국정보화진흥원에서 개최한 2020 데이터 크리에이터 캠프에 참가하면서 EDA의 중요성을 느꼈다. 모델링 예측도 중요하지만 데이터 탐색에 대한 질문을 많이 해주시면서 중요성
ssung-22.tistory.com
- 변수 특성에 맞게 그릴 수 있는 그래프 (시각화)
