[통계 데이터분석] 데이터 요약- 범주형 변수 (기술통계 관점) ⭕
빈도표 (table 함수)
: 데이터의 대략적인 분포를 손쉽게 파악 가능
: 범주별 출현 빈도를 나타내는 요약표를 얻을 수 있음
: 최빈값 (mode)은 가장 높은 빈도를 갖는 변수값
교차표
: 두 변수의 범주별 조합 빈도를 조사하여 작성한 2차원의 테이블
: 두 범주형 변수 간의 관계를 파악하고자 할 때 유용
1. 데이터 요약- 범주형 변수
library(MASS)
#survey 데이터셋 사용
str(survey)
# 응답자의 흡연 습관, 범주화
levels(survey$Smoke)
-> Smoke 변수는 'factor 데이터 구조' (범주형 데이터)/ 4 level


-> table( ) 함수를 이용해서 Smoke 변수에 대한 '네 가지 레벨 빈도'를 구할 수 있음
frqtab <- table(survey$Smoke) #frqtab 이라는 변수에 빈도 저장
frqtab
class(frqtab) #table객체 반환
frqtab[2] #두 번쨰 범주에 대응되는 값 출력됨
-> table 객체는 '배열, 행렬과 동일한 데이터 구조'를 갖음!

-> 배열에서와 마찬가지로 인덱스 나 이름을 이용해서, 특정 원소를 선택할 수 있음

1-1) 범주형 변수 -> 최빈값(가장 높은 빈도) 이용!
# max() 함수 이용하여 '최빈값' 파악하기!
frqtab== max(frqtab) #TRUE 에 해당하는 것= 최빈 범주!
frqtab[frqtab== max(frqtab)] #TRUE 에 해당하는 범주의 변수값 추출 가능!
names(frqtab[frqtab== max(frqtab)]) #해당 범주의 이름만 추출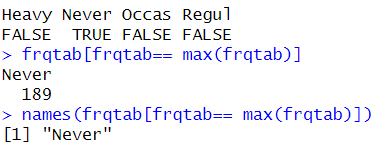
- 최빈값 위치를 인덱스로 반환
# which.max() 함수 = 주어진 벡터의 최빈값 위치를 인덱스로 반환
# which.max()의 인수: 빈도표 지정
which.max(frqtab)
#생성한 빈도표의 벡터에다가 인덱스로 주게 되면 '두번째 위치에 있는 범주' 출력
# frqtab[2] 값이랑 같음
frqtab[which.max(frqtab)]
names(frqtab[which.max(frqtab)])
- 빈도에 대해서 비율 구하기
# prop.table( ) 함수 = 빈도가 비율로 환산되는 함수
#prop.table()의 인수= 빈도표 지정
frqtab.prop <- prop.table(frqtab)
frqtab.prop # 네 개의 범주의 비율 추출
frqtab.prop["Never"] #특정 범주만의 비율 추출
frqtab.prop * 100 #백분율로 환산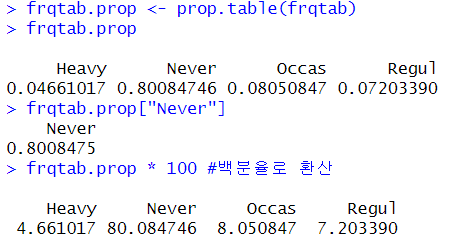
-> 특정 값이 출현하는 비율을 알고자 할 때, 논리연산 이용! (논리값 TRUE:1/ FALSE:0 변환)
-> 논리값을 이용하여, 특정 값의 출현 여부를 먼저 식별한 다음, mean( )함수로 평균 구하기 [상대적 빈도, 비율]
(비흡연자에 대해서 MEAN 구하기)
#1. '비흡연자'에 대해 논리연산 식별
survey$Smoke== "Never" #TRUE: 비흡연자/ FALSE: 흡연자
#평균값은 'TRUE'인 값의 비율을 의미하고, 이는 [비흡연자의 비율]이 됨
mean(survey$Smoke== "Never") #결측값 존재시, NA 가 출력됨
mean(survey$Smoke== "Never", na.rm= TRUE)

=> 80% 정도가 '담배를 피우지 않는 사람'의 비율
- anorexia 데이터셋 이용= 식욕부진증 환자의 '치료 전'과 '치료 후'의 몸무게 기록 데이터셋
head(anorexia)
( 치료 전_Prewt, 치료 후 몸무게_Postwt 변수 비교!)
- 치료 후 몸무게가 증가한 식욕부진증 환자의 비율 구하기 (mean)
#치료 후 몸무게가 증가한 식욕부진증 환자-> 논리연산
anorexia$Postwt > anorexia$Prewt # TRUE: 치료 후 몸무게 증가
mean(anorexia$Postwt > anorexia$Prewt)
- mammals 데이터셋 이용 = 동물들의 두뇌 무게와 몸무게가 저장된 데이터셋

- 편차 계산 (값- 평균)
- 편차의 절댓값 이 표준편차 보다 큰 경우
- 두뇌의 무게가 몸무게보다 상대적으로 매우 크거나, 매우 작은 동물 식별
= 두뇌의 무게가 평균으로부터 두 개의 표준편차보다 큰 동물의 비율 계산
#각 동물별로 두뇌 무게의 평균과의 편차 계산
mammals$brain - mean(mammals$brain)
# 절댓값으로 계산 ('차이'에 집중= 양수,음수 포함!)=> 절댓값 편차 > 표준편차
# 두뇌의 무게가 평균으로부터 두 개의 표준편차보다 큰 동물= TRUE
abs(mammals$brain - mean(mammals$brain)) > 2*sd(mammals$brain - mean(mammals$brain))
mean(abs(mammals$brain - mean(mammals$brain)) > 2*sd(mammals$brain - mean(mammals$brain)))
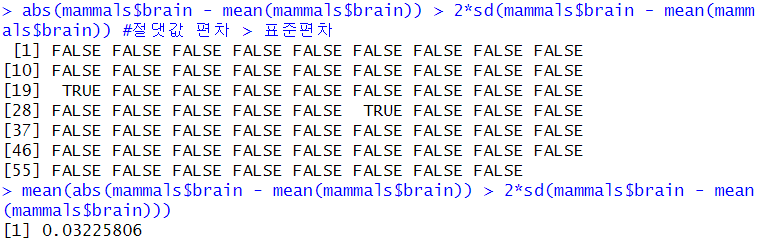
=> 두뇌의 무게가 상대적으로 매우 크거나 작은 동물 = 3%
- SP500 데이터셋 이용 = SP500 지수 수익률이 일자별로 저장되어 있음

- SP500 수익률이 전날보다 증가한 비율 계산 = 연속된 두 날짜의 수익률의 차이가 0보다 큰 일자의 비율을 계산
- diff( ) = 주어진 벡터로부터 연속된 두 숫자의 차이 계산 함수
diff(SP500) #연속된 두 일자 간의 차이 계산
diff(SP500) > 0 #수익률이 전일보다 증가한 경우
mean(diff(SP500) > 0 #TRUE 에 해당되는 날짜의 비율을 계산 가능


- 빈도표를 이용하여 '변수의 범주 별 빈도'를 파악하면, 개별 변수의 범주 별 분포를 대략적으로 이해할 수 있음
- 두 변수의 범주 조합에 따른 조합 별 빈도를 살펴보면, 두 변수 간의 관계를 이해하는 데 도움이 됨
- 교차표는 두 변수의 범주별 조합 빈도수를 조사해 작성한 2차원의 테이블을 의미
* 교차표 (두 범주형 변수 간의 관계를 파악하고자 할 때 유용하게 활용할 수 있음)*
- Arthritics 데이터셋 이용 ( 루마티스 관절염 치료제 효능에 대한 실험 데이터 )
install.packages("vcd")
library(vcd)
str(Arthritis)
# Arthritics 데이터셋은 다섯 개의 변수로 구성 되어 있음 = ID/ Treatment/ Sex/ Age/ Improved
# Treatment 변수 = 치료제 <- 범주형 변수 (펙터)
# Improved 변수 = 치료효과 <- 범주형 변수 (펙터)
levels(Arthritis$Treatment)
levels(Arthritis$Improved)
# Treatment 변수= 위약 투약을 나타내는 'Placebo'/ 신약 투약을 나타내는 'Treated', 두 개의 레벨로 저장
# Improved 변수= 각 처치에 따른 치료 효과
1-2) 범주형 변수 교차표 만들기 - [Treatment 와 Improved 변수 간의 교차표]
- table () 함수 이용 <- 이 함수에 두 개의 범주형 변수를 차례로 지정하게 되면 각각 행과 열로 배치가 되는 교차표가 생성됨
crosstab <- table(Arthritis$Improved, Arthritis$Treatment)
crosstab
# table() 함수의 첫 번째 인수는 행 변수를 나타내고, 두 번째 인수는 열 변수를 나타냄
-> 행에는 Improved 변수의 범주들이 배치되고, 열에는 Treatment 변수의 범주
# 셀 값은 '대응되는 두 개의 범주가 교차하는 빈도수를 의미함'
-> '21' 이란 숫자는 '신약을 투입한 환자들 가운데서 증상 개선 효과가 Marked(현저하게) 좋아진 환자의 수를 의미함
# 교차표는 행렬과 같은 형태로 출력이 되기 때문에 '행렬형 인덱스'를 이용해서 특정 셀 값을 추출할 수 있음
: 행과 열에 있는 범주를 콤마(,)를 중심으로 -> 대응되는 셀값을 추출할 수 있음
crosstab["Marked", "Treated"]
table(Arthritis$Improved, Arthritis$Treatment)crosstab["Marked", "Treated"]
table(Arthritis$Improved, Arthritis$Treatment,
dnn= c("Improved", "Treatment")) #dnn 인수에 '행과 열 이름 지정'

- xtabs()함수 이용 가능 = 교차표 생성 가능 함수.2 (기본적으로, 행과 열의 이름이 같이 출력되는 결과 추출)
-> formula 인터페이스 방식으로 행과 열의 변수를 지정/ formula 의 오른쪽에 '행의 변수와 열의 변수를 +로 연결해서 지정 - -> 행과 열의 이름이 함께 출력됨 (Improved, Treatment )
crosstab <- xtabs(~ Improved + Treatment,data= Arthritis)
crosstab
# ~(tilde)의 오른쪽에 행의 변수와 열의 변수를 차례대로 + 로 연결해서 지정

- 교차표 생성 시, 교차표의 행과 열에 대한 빈도 합 계산 가능 (margin.table() 함수 이용)
- margin.table() 함수의 첫 번째 인수 = 교차표를 지정
- margin.table() 함수의 두 번째 인수 = margin 인수 지정
# margin= ) 1을 지정하면 행의합/ 2를 지정하면 열의 합
margin.table(crosstab, margin = 1)
margin.table(crosstab, margin = 2)

- prop.table() -> 행의 비율과 열의 비율을 산출할 수 있음
# margin 인수에 1을 지정한 prop.table()함수를 실행하게 되면,
# 'margin= 1' -> 행이 100%인 비율의 교차표 (행의 합이 1)가 만들어짐 = Improved 의 세 개의 범주별로 각 범주 합이 100%
# 'margin=2' -> 열이 100%인 비율의 교차표 (열의 합이 1)가 만들어짐 = Treatment 의 두 개의 범주별로 각 범주 합이 100%
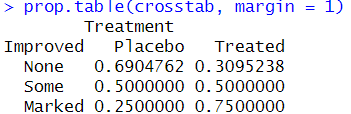

# 열의 비율의 교차표를 보면, Treatment 변수의 Treated 범주의 Marked
= 신약이 투입된 환자에 대해서 증상 개선 효과가 '현저하게 호전된 환자'의 비율이 51.2%라는 걸 확인 가능
# 반면에, 위약이 투입된 경우 'Placebo 범주에 대응되는 환자' 가운데 16.2 % 만이 Marked 수준의 현저한 증상 개선 효과를 보임
[열의 방향으로 100% 만드는 것의 중요성] - 표에 대한 설명
- 정보 전달의 내용이 달라질 수도 -> 순서 의미있게 배치해야 함!(원인:열, 결과:행)
-> 열의 비율을 계산하면 설명하기 쉬움!
원인)치료약 -> 결과)치료결과
-> 예- [성별에 따른 선호 음식: 성별(원인) -> 선호음식 (결과)]
- 교차표상의 개별 셀의 비율을 계산
- prop.table()함수의 margin 인수에 아무것도 지정하지 않고 교차표만을 지정하면 됨
prop.table(crosstab)
- addmargins() 함수 이용: 교차표의 행과 열의 빈도합을 포함시키기
addmargins(crosstab, margin=1)
addmargins(crosstab, margin=2)

# margin=1, 행의 값들을 모두 합한 '합계 행'을 의미
# margin=2, 열의 값들을 모두 합한 '합의 열'을 의미
- addmargins() 함수에 crosstab 교차표만을 지정하고, margin 인수를 지정하지 않으면 두 변수 모두에 대한 합의 행과 열을 구함
addmargins(crosstab)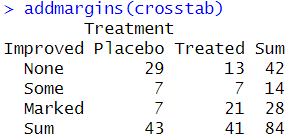
# 100%를 나타내는 열과 행을 생성해서 교차표 해석에 도움을 줌
- addmargins(prop.table())
- 행과 열의 비율이 100%가 되는 '행 혹은 열의 비율의 교차표'를 만들었을 경우엔, 합계가 100%가 된다는 것을 보여줌
addmargins(prop.table(crosstab, margin=2), 1)
addmargins(prop.table(crosstab, margin=1), 2)

- 교차표 생성 -> table(), xtabs(), gmodels 패키지에 포함된 CrossTable() 함수 이용
install.packages("gmodels")
library(gmodels)# CrossTable의 첫번째 인수= 교차표 상의 행에 배치될 변수 지정
# CrossTable의 두번째 인수= 교차표 상의 열에 배치될 변수 지정
# CrossTable 함수는 많은 인수들을 제공함.
# -> 인수 지정을 통해서 '교차표에 포함될 정보를 선택할 수 있음' or '불필요한 정보는 표시 안 되게 할 수 있음'
# -> 'chisq 톨계량 값은 필요가 없기 때문에 'FALSE'
# -> dnn 인수 지정을 통해 '교차표의행과 열에 표시될 이름'지정
CrossTable(Arthritis$Improved, Arthritis$Treatment, prop.chisq= FALSE,
dnn= c("Improved", "Treatment" ))

# CrossTable() 첫번째 인수에 교차표상의 행에 배치될 변수를 지정, 두번째 인수에 열에 배치될 변수를 지정함
-> 인수 지정을 통해서 '교차표에 포함될 정보'를 선택할 수 있음
-> 때로는, 불필요한 정보를 또 표시가 안 되도록 지정할 수 있음
(예, chisq(카이스퀘어어)통계량 값은 필요가 없기 때문에, prop.chisq= FALSE 로 지정하여 표시가 되지 않도록 함)
# dnn 인수 지정을 통해서 '교차표의 행과 열에 표시될 행, 열의 이름을 지정'
1) 셀의 관측값의 개수, 2) 행의 비율, 3) 열의 비율, 4) 전체 셀의 비율
1-3) 범주형 변수가 세 개 이상 시- 다차원 테이블 생성
# 2차원 테이블 생성- table(), xtabs() 함수 모두 다차원 테이블 생성 가능
multtab <- table(Arthritis$Improved, Arthritis$Sex, Arthritis$Treatment)
multtab
# 차원이 3개 있을 경우- 첫 번째 차원을 행/ 두번째 차원- 열/ 세번째 차원- 테이블
-> 다차원일 경우, 배열에서는 테이블별로 행렬을 하나씩 출력
# 세번째 차원에 있던 Treatment의 두 개의 범주별로 Improved, Sex 변수를, 행과 열로 하는 교차표 만들기
multtab <- xtabs(~ Improved + Sex + Treatment, data= Arthritis)
multtab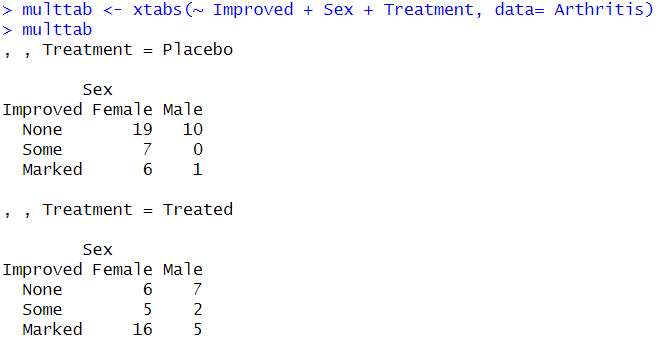
- ftable() 함수 이용 - 더 단순하고, 보기 좋은 형태로 출력 가능
# ftable() 함수의 인수= xtabs() 함수나 table() 함수로부터 생성한 다차원 테이블을 지정
ftable(multtab)
# ftable() 함수를 이용하게 되면, 행과 열에 들어갈 변수를 지정함
-> 행에 1차원과 2차원에 지정된 범주형 변수가 배치됨,
-> 열에 3차원에 지정된 범주형 변수가 배치됨
ftable(multtab, row.vars= c(2,3))#'row.vars' 인수= 두번째 차원(Sex 변수)과 세번째 차원(Treatment 변수)을 행에 배치
-> Sex 변수와 Treatment 변수가 행에 배치되는 교차표 생성/ 지정되지 않은 첫번째 차원(Improved 변수가)은 열로 배치됨

ftable(multtab, row.vars= c(2,3), col.vars)
# ftable() 함수는 table 객체를 인수로 받을 수도 있지만, 데이터프레임으로부터 직접 테이블을 생성할 수도 있음
# ftable() 함수에 필요한 열을 포함하고 있는 데이터프레임 지정
# ftable() 함수의 첫번째 인수= 필요한 열(세 개)을 포함하고 있는 데이터프레임 지정
# ftable() 함수의 두번째 인수(row.vars 인수)= 행으로 배치될 변수를 지정
ftable(Arthritis[c("Improved","Sex","Treatment")],
row.vars= c(2,3))
-> margin.table( )함수 = 3차원 이상으로 확장 가능!
# multab <- xtabs(~ Improved + Sex + Treatment, data= Arthristis)
# -> Improved(차원 1), Sex(차원 2), Treatment(차원 3)
# margin.table()함수의 margin인수 = 세 개의 차원 지정(multab)
margin.table(multtab, 1)
# -> '1'지정하면, 차원 1인 'Improved' 변수에 의한 빈도합 계산
margin.table(multtab, 2)
# -> '2'지정하면, 차원 2인 'Sex' 변수에 의한 빈도합 계산
margin.table(multtab, 3)
# -> '3'지정하면, 차원 2인 'Treatment' 변수에 의한 빈도합 계산
-> 복수의 차원을 지정해서, 복수의 차원에서 만들어지는 교차 셀에 대한 빈도합도 출력 가능!
margin.table(multtab, c(1,3))
# 첫번째 차원과 세번째 차원이 이루는 교차 셀에 대한 빈도합을 출력함
-> 첫번째: Improved, 세번째: Treatment (이 두개의 차원에서 만들어지는 교차셀의 빈도합 계산)
# 이때, 인덱스로 주어지지 않은 두번째 차원인 Sex에 대해서 합산이 이루어짐
# 성별과 무관하게 두 개의 차원에서 만들어지는 교차셀의 빈도합 출력 가능
# 복수의 차원을 인수로 지정하게 되면, 변수들 간의 관계를 보여주는 유용한 교차표 생성가능
(예: 성별과 치료제의 조합에 따라서 치료효과의 차이가 있는지를 보여주는 교차표 생성 가능)
# margin 인수에 '성별 차원'과 '치료제 차원'을 지정해서 두 개의 교차셀에서 만들어지는 비율 출력
# 성별이 2차원, 치료제가 3차원
ftable(prop.table(multab, c(2,3))
-> 신약을 처방받은 여성 가운데서 59.2% 는 현저한 증상 개선 효과를 보이고 있는 반면에,
신약을 처방받은 남성 가운데는 35.7% 만이 현저한 증상 개선 효과를 보이는 것을 볼 수 있음
-> 교차표 => 신약의 처방 효과가 남성보다는 여성한테서 더 잘 나타남을 확인 가능!
자료출처:
https://www.youtube.com/watch?v=3qQM4xgHPic&list=PLY0OaF78qqGAxKX91WuRigHpwBU0C2SB_&index=3