(교차표를 이용하면 범주형으로 수집된 두 변수의 범주 조합에 따른 조합별 빈도를 살펴볼 수 있으며, 이를 통해 두 변수 간의 관계를 파악할 수 있음.)
- 독립성 검정 은 두 범주형 변수 간의 관련성이 모집단에서 존재하는지 검정
(예: 연령대와 선호하는 음식 종류 간의 관계 검정 -> 20대: 중식, 30대: 양식, 40대: 한식을 선호하는 결과 -> 연령대 와 선호하는 음식 간에 서로 관련성이 있다)
- 적합성 검정 은 범주형 변수가 하나 있을 경우, 그 하나의 범주형 변수에 포함되는 범주별 빈도를 바탕으로 모집단에서 기대되는 비율 분포가 존재하는지 검정
(예: 이동 통신 회사가 a, b, c 세 개가 있을 때 100명의 소비자를 대상으로 어느 이동통신사에 가입해 사용하고 있는지를 물어보는 경우, 50명: a, 30명: b, 20명: c 라는 결과는 a,b,c, 3개 회사의 시장 점유율 비율 = 5: 3: 2 => 이 비율이 모집단에서도 유지되는지)
1-1. 카이제곱 검정: 교차표상의 응답 빈도를 바탕으로 수행됨
예: 안전벨트 착용과 승객 안전 간의 관계에 관심이 있다고 했을 때, 두 변수 간의 교차표를 생성함.
교통사고 환자의 안전벨트 착용 유무와 환자 상태를 조사하여 교차표를 얻었음)
1) 데이터를 행렬 형식으로 저장함 -> 행과 열에 각각 환자의 상태와 안전벨트 착용 유무를 나타낸 범주명을 지정한 다음에 생성한 교차표를 확인해보면, 이런 교차표를 얻을 수 있음 -> 행: 환자의 상태가 배치됨(경상,중상,사망)/ 열: 안전벨트의 착용 유무가 배치됨(O,X)
: 안전벨트 착용 유무에 따라서 각 환자의 상태의 차이가 클 때, '안전벨트 착용 유무와 환자의 상태 간의 관계가 있다'고 생각해볼 수 있음
-> but: 이런 간단한 교차표를 가지고는 '두 변수 간의 관계' 파악이 쉽지 않음!
-> why: 안전벨트를 착용한 사람 수와 착용하지 않은 사람 수가 다르기 때문에 직접 수치를 가지고 비교할 수 없음
-> 비율을 정했을 땐, 비율을 바탕으로 해서 '안전벨트 착용 유무가 환자의 상태에 미치는 영향을 더 쉽게 우리가 파악해 볼 수 있음'
3) 두 변수 간의 관계를 보다 잘 파악하기 위해선 : 교차표의 행과 열의 합을 추가한 다음에 100%로 척도 조정된 열의 비율을 계산
#교차표에 행과 열의 합을 추가하기
addmargins(survivors)
-> 총 3,869 명의 환자: 안전벨트 착용자는 1,641명이고, 미착용자 2,228 명
: 안전벨트 착용자 가운데 경상자는 1,443명 이고 (비율: 87.9%)/ 미착용자 가운데 경상자는 1,781명 (비율: 79.9%)
prop.table( ) 함수 : 비율의 교차표 생성 함수
-> 안전벨트를 착용한 사람과 착용하지 않은 사람의 숫자가 다르기 때문에 [열의 비율이 100%가 되는 비율의 교차표 생성]
-> 열을 기준으로 행 집단 간의 차이 분석
addmargins(survivors, 2)
# prop.table() 함수의 첫번째 인수: addmargins(survivors, 2)
# prop.table() 함수의 두번째 인수(margin 인수): '2' 지정 -> 열의 합계가 100%인 비율의 교차표 생성
prop.table(addmargins(survivors, 2), 2)
# 합계가 100%가 되는 행을 추가적으로 만들기
addmargins(prop.table(addmargins(survivors, 2), 2), 1)
(1) 안전벨트를 착용한 사람 1,641명을 100%로 맞춤 -> '경상자, 중상자, 사망자'의 비율 계산
(2) 안전벨트를 착용하지 않은 사람 2,228명을 100%로 맞춤 -> '경상자, 중상자, 사망자'의 비율 계산
= 경상자의 비율 (79.9%), 중상자의 비율 (14%), 사망자의 비율 (6%)
전체의 Sum 에 대한 합계: 경상자 (83.3%), 중상자 (11.9%), 사망자 (4.7%)
-> 최종적으로 생산된 비율의 교차표 : 합계의 합까지 나타나 그러한 열의 비율이 100% 가 되는 교차표를 얻을 수가 있음
-> 생성한 교차표를 이용해서 '안전벨트의 착용과 승객의 안정 간의 관련성' 유추해보기
[결과] (1) 안전벨트 착용자 가운데 경상자는 1,443명 이고 (비율: 87.9%)/ 미착용자 가운데 경상자는 1,781명 (비율: 79.9%) -> 경상자의 비율: 안전벨트를 착용한 경우 > 그렇지 않은 경우 (2) 안전벨트 착용자 가운데 중상자는 151명 이고 (비율: 9.2%)/ 미착용자 가운데 중상자는 312명 (비율: 14%) -> 중상자의 비율: 안전벨트를 착용한 경우 < 그렇지 않은 경우 (3) 안전벨트 착용자 가운데 사망자는 47명 이고 (비율: 2.9%)/ 미착용자 가운데 사망자는 135명 (비율: 6%)
# 상대적인 비교를 하기 위해서 (안전벨트 착용 유무의 비율을 각각 100% 로!)
# prop.table() 함수 = 비율 계산 함수
survivors.prop <- prop.table(survivors, 2)
barplot(survivors.prop*100, las=1, col=c("yellowgreen", "lightsalmon", "orangered"),
ylab="Percent", main="Percent of Survivors")
2. x^2 검정 (통계적 검정)
- x^2 검정은 범주형 변수 간 관련성이 모집단에서 존재하는지 검정
- x^2 검정은 기대빈도와 관측빈도의 비교를 통해 계산되는 X^2 값 (X^2 value, X^2 statictic) 을 가설검정을 위한 검정통계량으로 사용
-> 관측빈도: 교차표상의 실제빈도를 의미함
-> 기대빈도: 변수 간 서로 관련성이 없을 때(귀무가설이 사실이란 가정 하에) 기대할 수 있는 예상빈도를 의미함
(귀무가설이 사실이라면, 안전벨트 착용자와 미착용자는 사고 이후의 상태에 대해 동일한 패턴을 보이게 될 것
= 사고 이후 환자 상태의 비율이 안전벨트 착용자와 미착용자 간에 동일하다는 의미를 가짐)
- X^2 검정 결과가 통계적으로 유의하면 변수 간 관련성이 존재
[X^2 값은 교차표를 바탕으로 계산함] - 교차표의 각 셀 값: 기본적으로 관측 빈도를 의미함 (관측빈도를 바탕으로 해서 귀무가설이 사실인 가정 하에서 = 두 범주형 변수 간의 아무런 관련이 없다는 가정에서 기대할 수 있는 기대 빈도를 각 셀마다 계산함_ -> 각 셀: 관측 빈도와 기대 빈도의 쌍이 계산 됨 - 관측 빈도와 기대 빈도의 쌍을 이용해서 이러한 상식에 대해서 X^2 값 계산 가능 - 각 셀에 대해서 관측 빈도와 기대 빈도의 차이를 계산하고 그것을 제곱함. 그리고 기대빈도로 나눔 -> 이러한 계산을 모든 셀에 대해서 수행하고 모든 셀에 대해서 합산하게 되면 x^2 값을 구할 수 있음 -> 이렇게 계산된 X^2 값은 ' X^2_ chisq ' 라는 분포를 따름 - X^2_ chisq 분포는 '자유도'에 따라서 분포의 모양이 달라지고, 대체로 오른쪽으로 긴 꼬리를 갖음 - X^2_ chisq 분포의 자유도는 '교차표를 구성하는 두 변수의 범주의 개수'에서 결정됨 -> 자유도 = (행 변수의 범주의 개수 -1) X ( 열 변수의 범주의 개수 -1) -> 예) 행 변수의 범주 개수: 3 / 열 변수의 범주 개수: 2 이기에 => (3-1) X (2-1) - 표본으로부터 X^2 값을 산출하고 나서 이 X^2 값이 귀무가설이 사실인 가정 하에서 X^2_ chisq 의 분포 상에서 얼마나 나타나기 어려운 희박한 경우인지 혹은 흔하게 관찰될 수 있는 경우인지 평가하는 가설 검정 수행'
[X^2 검정 결과_ X^2 값 계산 : 관측빈도와 기대빈도의 차 계산]
-> 두 차이가 클 때: 관측 빈도와 기대 빈도의 차이가 클 땐 '기대 빈도는 귀무가설이 사실이란 가정 하에 만들어진 값이기 때문에 우리가 실제로 표본으로부터 관측빈도와 많이 다르다는 것 (귀무가설이 아닐 가능성이 높다는 얘기)
-> 두 차이가 없고, 유사할 때: 극단적으로 관측 빈도가 기대빈도와 같아 분자값이 '0' 이 나올 땐, 귀무가설이 사실이란 가정 하에서 만들어진 기대빈도와 실제 관측 빈도가 같다는 얘기 (귀무가설이 맞을 가능성이 높다는 얘기)
[결과] - X^2 값이 크면 클수록 '귀무가설 기각/ 대립가설 채택' - X^2 값이 작으면 작을수록 '귀무가설 채택'
[기대빈도 산출 - 귀무가설이 사실이란 가정하에서 우리가 기대할 수 있는 빈도] 귀무가설: 안전벨트의 착용 유무와 환자 상태 간의 관련성은 없다
(1) 환자의 상태별 비율을 파악함 - 교차표 확인 : 경상자 (83.3%), 중상자 (12%), 사망자 (4.7%) -> 귀무가설이 사실이라면 이러한 비율은 안전벨트 착용 여부와 관계없이 착용자와 미착용자 집단 모두에게서 동일하게 나타날 것으로 기대할 수 있음 (비율은 동일하더라도 조사에 참여한 안전벨트 착용자와 미착용자의 수가 같지 않으면 환자 상태 빈도 자체는 다를 수 있음)
(2) 기대빈도 계산 : 각 환자 상태 비율에 안전벨트 착용자 및 미착용자의 수를 곱하여 구할 수 있음 (환자 상태별로 기대빈도를 구해봄) ▶ 안전벨트 착용자의 경상 기대빈도 (경상자수 x 총 안전벤트 착용자수)= 83.3% X 1641 = 1367.0 ▶ 안전벨트 미착용자의 경상 기대빈도 (경상자수 x 총 안전벤트 미착용자수) = 83.3% X 2228 = 1855.9 ▶ 안전벨트 착용자의 중상 기대빈도 (중상자수 x 총 안전벤트 착용자수) = 12% X 1641= 196.9 ▶안전벨트 미착용자의 중상 기대빈도 (중상자수 x 총 안전벤트 미착용자수) = 12% X 2228 = 267.4 ▶ 안전벨트 착용자의 사망 기대빈도 (사망자수 x 총 안전벤트 착용자수) = 4.7% X 1641 = 77.1 ▶안전벨트 미착용자의 사망 기대빈도 (사망자수 x 총 안전벤트 미착용자수) = 4.7% X 2228 = 104.7
(3) 관측빈도에 대응되는 기대 빈도 구하기 (관측빈도와 기대빈도 쌍을 이용해서 X^2 값 산출 가능) -> 표본으로부터 산출된 X^2 (카이스퀘어) 값이 귀무가설이 사실이라는 X^2 분포 상에서 얼마나 나타나기 어려운 희박한 경우인지 혹은 흔하게 관찰할 수 있는 경우인지를 평가하게 됨 -> 귀무가설이 사실) X^2 값 은 '0' 에 가까운 작은 값을 가져야 함 (환자의 상태는 안전벨트 착용 여부에 영향을 받지 않기 때문에, 관측빈도는 기대빈도와 유사한 값을 가질 것)
(1-1) X^2 값에서의 유의 확률을 구한 다음에 유의수준 0.05 와 비교함 -> 관측된 X^2 값의 확률이 유의수준 0.05 보다 작으면 '귀무가설 기각' (1-2) 유의수준 0.05 에서의 x^2 값을 구한 다음에 관측된 X^2 값과 비교함 -> 관측된 X^2 값이 유의수준 0.05에 대응되는 x^2 값보다 크면 귀무가설을 기각함
pchisq( )함수: 특정 X^2 값에 대응되는 확률을 구할 수 있음
qchisq( )함수: 특정 확률에 대응되는 값을 구할 수 있음
# pchisq()의 첫번째 인수= X^2 값 지정
# pchisq()의 두번째 인수= 자유도 지정 (행 범주의 갯수-1) * (열의 범주의 갯수-1)
pchisq(45.91, df=(3-1) * (2-1)) #45.91 이하의 영역이 계산됨
pchisq(45.91, df=(3-1) * (2-1), lower.tail= FALSE) #45.91 이상의 영역이 계산됨
# qchisq()의 첫번째 인수= 유의수준 0.05 값 지정
# qchisq()의 두번째 인수= 자유도 지정 (행 범주의 갯수-1) * (열의 범주의 갯수-1)
qchisq(0.05, df=(3-1) * (2-1), lower.tail= FALSE)
2. 독립성 검정
- 독립성검정은 두 범주형 변수가 서로 독립인지 검정 (독립이라는 것: 두 변수가 서로 관련이 없다는 것을 의미함)
(예: 성별과 선호하는 도서 장르가 서로 아무런 관련이 없을 때, 이 두 변수가 서로 독립이라고 말함)
귀무가설: 두 변수는 독립이다 (관련이 없다)
대립가설: 두 변수는 독립이 아니다 (관련이 있다)
-> 독립성검정은 'X^2 (카이제곱) 검정 절차에 따라 두 변수의 범주 조합별 빈도를 기록한 교차표를 토대로 수행됨
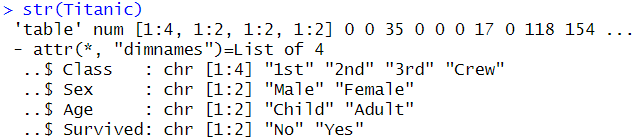
str(Titanic)
Titanic
-> 타이타닉호 탑승객의 승객 구분 (1등실, 2등실, 3등실, 승무원)에 따라 생존율에 있어서 차이가 있는지 검정
[ table(다차원) 객체에 저장된 데이터셋을 이용하여 독립성 검정 ]
1) 검정하고자 하는 변수로 이루어진 2차원 형태의 교차표로 데이터를 변환해야 함
margin.table( ) 함수: 승객 구분과 생존 여부 간 교차표 작성에 필요한 두 개의 차원만을 추출하여 별도의 table 객체로 저장
# margin.table()함수의 첫번째 인수: 테이블 지정 (Titanic)
# margin.table()함수의 두번째 인수: 추출하고자 하는 차원 지정
# -> margin=c(4, 1) 에서 '4'차원: 생존 여부/ '1'차원: 승객 구분을 나타내는 차원
Titanic.margin <- margin.table(Titanic, margin=c(4, 1))
Titanic.margin
- 2차원 교차표 -> 행: 생존 여부/ 열: 승객 구분
addmargins( ) 함수:행과 열의 합 추가
prop.table( ) 함수: 승객 구분 별로 생존율에 있어 차이가 있는지 확인하기 위해서 열의 비율도 계산
addmargins(Titanic.margin)
# 열의 비율 계산 : 교차표에 열의 합계 추가
addmargins(Titanic.margin, 2)
# 열의 비율 계산 : 비율 계산
prop.table(addmargins(Titanic.margin, 2), 2) #열의 합계가 100%이 되는 교차표 생성
addmargins(prop.table(addmargins(Titanic.margin, 2), 2), 1) # 행과 열의 합계가 100%
# chisq.test()의 인수= 교차표 지정
chisq.test(Titanic.margin)
-> 값이 유의수준 0.05 에 비해서 매우 작기 때문에 승객 구분과 생존 여부 간의 관계가 없다는 귀무가설을 기각할 수 있음
(승객 구분에 따라서 생존율엔 차이가 존재함)
-> 두 범주형 변수 간의 관계가 없다는 '귀무가설을 기각'하면 -> 이들 간의 관련성에 강도를 평가할 수 있음
vcd 패키지에 포함되어 있는 assocstats 함수 이용: 관련성에 강도를 나타내는 지표
library(vcd)
assocstats(Titanic.margin)
-> [Phi-Coefficient/ Contingency/ Cramer's V] 지표 값들의 값이 클수록 두 변수 간의 관련성이 크다는 것을 나타냄
- 범주형 변수 간의 관계는 '모자이크 도표'를 이용해서 시각화할 수 있음
vcd 패키지에 포함되어 있는 모자이크 함수 이용: 모자이크 도표 생성 (범주형 변수 간의 관계)
library(vcd)
windows(width=7.0, height=5.5)
# mosaic()함수의 첫번째 인수: 교차표 지정
# mosaic()함수의 추가 인수(shade 인수): TRUE
# -> (귀무가설을 기각하는 데 있어서 어떤 범주 쌍이 더 큰 기여를 하는지를 색깔로 구분)
mosaic(Titanic.margin, shade=TRUE, legend=TRUE)
mosaic(~ Survived + Class, data=Titanic.margin, shade=TRUE, legend=TRUE)
-> 모자이크 도표 에서 '직사각형의 크기'는 교차표 상의 셀 값에 비례함
: 파란색 계통의 셀과 빨간색 계통의 셀이 존재함 (범례- 피어슨 잔차 크기에 따라 셀을 색상으로 구분해 줌)
-> 관측빈도 와 귀무가설이 사실이라는 가정하에서 계산된 기대빈도 간의 차이를 의미함
: 관측빈도와 기대빈도의 차이가 양수의 큰 값일수록 파란 색으로 표현됨 (관측빈도> 기대빈도)& 관측빈도와 기대빈도의 차이가 음수의 큰 값일수록 빨간색으로 표시됨 (관측빈도 < 기대빈도)
-> 파란색이나 빨간색에 가까운 셀: 귀무가설을 기각하는데 크게 기여하는 셀
- 데이터프레임 형태로 저장된 데이터셋: 교차표 생성 과정 없이 검정 대상 변수에 직접 chisq.test( )함수를 적용함으로써 독립성검정을 수행 가능!
MASS 패키지에 포함된 survey 데이터셋의 Sex 변수와 Fold 변수를 이용하여 독립성검정 수행
Sex (성별), Fold (팔짱을 끼었을 때 어느 쪽 손이 위쪽에 위치하는지를 나타냄)
성별에 따른 팔짱을 끼었을 때의 손 위치 차이 검정
library(MASS)
str(survey)
chisq.test( ) 함수: 내부적으로 교차표를 생성한 다음에 그 결과를 이용해서 독립성 검정 수행
chisq.test( ) 함수에 검증 대상 변수를 직접 지정 -> 데이터들은 벡터 형식으로 되어 있어야 됨
(예- 소비자단체에서 150명의 휴대전화 사용자를 대상으로 이용하고 있는 이동통신회사를 조사함.
-> 조사 결과) A 회사의 이용자 (60명), B 회사 (55명), C회사 (35명) 으로 집계되었음
-> 데이터를 이용하여 '세 이동통신회사의 시장점유율이 동일한지 검정'
: 관측한 빈도를 토대로 모집단에서의 집단별 비율 분포를 검정하는 것: 적합성 검정
chisq.test( ) 함수: 적합성을 검정하는 함수
이동통신회사의 시장점유율 관련 비율의 분포를 검증
검정 비율을 지정하지 않으면 검정 비율은 집단 간에 동일하다고 가정
# chisq.test()함수의 인수: 집단별 관측빈도와 함께 검정하고자 하는 집단별 비율을 인수로 지정
# chisq.test()함수의 인수: 세 이동통신회사 이용자수 지정
chisq.test(c(60, 55, 35))
# -> 검정비율을 별도로 지정하지 않았기 때문에 세 이동통신회사의 시장점유율은 동일하다고 가정
- 표본 데이터를 바탕으로 '세 이동통신 회사의 시장 점유율이 동일한 지'를 chisq.test( ) 함수를 이용해서 검증 가능
-> 검정 결과를 유의수준 에 비교했을 때, 0.05 보다 작기 때문에 '귀무가설 기각'
-> 귀무가설: 세 이동통신회사의 시장점유율이 동일하다
- 한 시장조사 전문가가 세 이동통신회사의 시장점유율은 A회사 (45%), B 회사 (30%), C회사 (25%)라고 주장함
-> 위의 주장 검증
검정하고자 하는 검정 비율이 이제 더 이상 집단 간에 동일하지 않기 때문에 검정 비율을 인수로 지정해야 함
# 이동통신회사 가입자에 대한 표본 데이터를 변수로 저장
oc <- c(60, 55, 35)
# 검정하고자 하는 검정 비율을 null.p 라는 변수에 저장
null.p <- c(0.45, 0.30, 0.25)
# chisq.test() 함수의 첫번째 인수: 표본 데이터 지정
# chisq.test() 함수의 두번째 인수(p): 검증하고자 하는 검정 비율을 지정함
chisq.test(oc, p=null.p)
-> 검정 결과: p값이 유의수준 0.05 보다 크기 때문에 귀무가설을 기각할 수 없음
-> 시장조사 전문가의 주장은 타당하다고 볼 수 있음
(시장조사 전문가가 주장 a, b, c 3개의 회사의 시장 점유율 45%, 30%, 25% 라고 볼 수 있음)
- 소비자단체에선 '매년 이러한 동일한 조사 수행하고 있음'
-> 85명의 휴대전화 사용자 중에서 a 회사 이용자 (45명), b 회사 이용자 (25명), c 회사 이용자 (15명)
-> 올해의 조사결과가 작년 조사 결과와 동일하다고 할 수 있는지 적합성 검정을 통해서 검증 가능
# chisq.test() 함수의 인수(p): 검정 비율에 작년 시장 점유율을 지정함
chisq.test(oc, p=c(45, 25, 15)/85)
- 현재 표본 데이터를 바탕으로 해서 작년에 시장 점유율이 올해와 같은지 검정 가능
-> [검정 결과] p 값이 0.006 으로써 유의수준 0.05 보다 작은 값이기 때문에 귀무가설 기각, 대립가설 채택
-> 1년 동안의 시장 점유율에 있어서 변화가 있었다 라고 볼 수가 있음
- 다차원의 테이블 객체에 저장된 데이터셋에 대한 적합성 검증
1) 검증하고자 하는 변수를 추출해서 1차원의 벡터 형태로 만들어야 함
HairEyeColor 데이터셋 이용
머리 색깔과 눈 색깔, 성별 을 나타내는 세 개의 차원으로 구성되어 있음
margin.table( ) 함수 이용: 머리 색깔 데이터 추출
- 머리 색깔 분포에 대한 생리학자의 주장이 맞는지 적합성 검증을 수행해서 확인해볼 수 있음
(예: 생리학자- 미국의 인구 분포 상 검은색 머리 (25%), 갈색 머리(50%), 붉은색 머리(10%), 금발 머리(5%) 정도를 차지함)
# chisq.test()함수의 첫번째 인수: 표본데이터 지정
# chisq.test()함수의 두번째 인수(p): 검증하고자 하는 비율을 지정
chisq.test(hairs, p=c(0.25, 0.50, 0.10, 0.15))
-> p-값의 결과가 유의수준 0.05에 비해 매우 작은 값이기 때문에, 귀무가설 기각 + 대립가설 채택
-> 생리학자가 주장하는 이러한 머리 색깔의 분포 하에서는 표본 데이터와 같은 머리 색깔의 빈도 분포를 얻을 가능성이 희미함
-> 생리학자가 주장하는 머리 색깔의 분포는 받아들이기 어려움 (귀무가설을 받아들일 수 없음)
-> 비흡연자 (70&), 3가지 유형의 나머지 흡연자는 각각 10% 씩이라고 알려져 있다. 는 가설을 chisq.test( ) 함수를 이용해서 검정 가능
# chisq.test()함수의 첫번째 인수: 표본데이터 지정
# chisq.test()함수의 두번째 인수(p): 검증하고자 하는 비율을 지정
chisq.test(smokers, p=c(0.1, 0.7, 0.10, 0.10))
# -> 두번째 0.7 이 비흡연자를 나타내는 비율
-> p-값의 결과가 유의수준 0.05에 비해 작은 값이기 때문에, 귀무가설 기각 + 대립가설 채택