- 확률 = (사건이 발생할 경우의 수) / (표본공간 경우의 수), 확률 값 범위: 0 <= P(A) <= 1
조건부 확률
- P (A| B): 사건 B가 발생했다는 조건 아래서 사건 A가 발생할 조건부 확률
- P (A| B) = P(A 교집합 B) / P(B), 단 P(B) > 0
- 두 사건 A, B가 독립사건인 경우: P(B| A) = P(B), P(A| B)= P(A), P(A 교집합 B) = P(A) * P(B)
사건의 종류
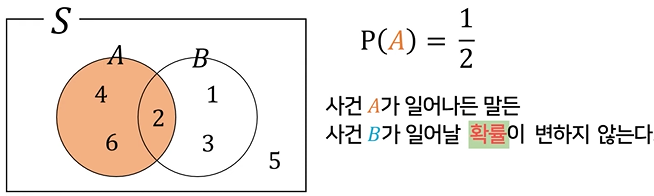
독립사건
- A의 발생이 B가 발생할 확률을 바꾸지 않는 사건 (사건 B 가 일어나든 말든 사건 A가 일어날 확률이 변하지 않음)
- 두 사건 A, B 가 독립이면
P(B| A) = P(B), P(A| B) = P(A), P(A 교집합 B) = P(A) * P(B) 성립 P(A 합집합 B)= P(A) + P(B)- P(A 교집합 B) = P(A) + P(B) - P(A) * P(B)
예) 주사위를 던질 때, 짝수의 눈이 나오는 사건 (A)/ 2 이하의 눈이 나오는 사건 (B)
배반사건
- 교집합이 공집합인 사건, 한 쪽이 일어나면 다른 쪽이 일어나지 않을 때의 두 사건
- A와 B가 배반사건이면, P(A 교집합 B) = 0, P(A 합집합 B) = P(A) + P(B)
- 예)동전 하나를 던져 앞면 나오는 사건, 뒷면 나오는 사건
종속사건
- 두 사건 A와 B 에서 한 사건의 결과가 다른 사건에 영향을 주는 사건
- 예) 음주와 사고 사건, P(A 교집합 B)= P(A| B) * P(B)
예) 주사위를 던질 때, 짝수의 눈이 나오는 사건 (A)/ 3 이하의 눈이 나오는 사건 (B)
확률변수와 확률분포
분포
- 일정한 범위 안에 흩어져 퍼져 있는 정도
확률변수
- Random variable, 확률 현상에 기인해 결과 값이 확률적으로 정해지는 변수
- 확률 현상: 어떤 결과물이 나올지 알지만, 가능한 결과들 중 어떤 결과가 나올지 모르는 현상
확률분포
- 어떤 확률변수가 취할 수 있는 '모든 값들과 그 값을 취할 확률의 대응관계'로 표시하는 것
확률분포의 종류
이산형 확률분포
- Discrete (별개의), 확률변수가 몇 개의 한정된 가능한 값을 가지는 분포
- 각 사건은 서로 독립이어야 함
-> 예) 이항분포, 베르누이분포, 기하분포, 포아송분포, 이산균등분포 등
(이산확률 분포의 확률함수 -> 질량함수)
연속형 확률분포
- Continuos, 확률변수의 가능한 값이 무한 개이며 사실상 셀 수 없을 때
-> 예) 정규분포, 지수분포, 연속균등분포, 카이제곱분포, F분포, t 분포 등
기댓값 = 어떤 과정을 무한히 반복했을 떄 평균으로 기대되는 값을 의미함
확률 질량 함수 PMF
- Probability Mass Fumction, PMF, y= f(x)
- 이산 확률 변수에서 특정 값에 대한 확률을 계산하기 위한 함수
- 주사위를 한 번 굴릴 때의 값을 나타내는 확률 변수가 x일 때, 특정 값에 대한 확률: P(X=x) = 1/6
확률 밀도 함수 PDF
- Probability Density Fumction, PDF, y= f(x)
- 연속 확률 변수에서, 특정 구간에 속할 확률을 계산하기 위한 함수
- 확률 밀도 함수 f(x)와 구간 [a,b] 에 대해 확률변수 X 가 구간에 포함될 확률
누적 분포 함수 CDF
- Cumulative Distribution Function, CDF, y= F(x)
- 어떤 확률 분포에 대해 확률변수가 특정값보다 작거나 같은 확률을 계산하기 위한 함
이산형 확률분포
베르누이분포 (배르누이 시행= 시행의 결과가 오로지 두 가지 )
- 매 시행마다 오직 두 가지의 가능한 결과만 일어난다고 할 때, 이러한 시행을 1회 시행하여 일어난 두 가지 결과에 의해 값이 각각 0과 1로 결정되며, 다음을 만족하는 확률변수 X 가 따르는 확률분포
- X가 1일 때의 확률을 p라고 하고, X가 0일 때의 확률을 q라고 할 때, p 가 0~1 사이의 값이고 q는 1-p 의 값을 가질 때의 X가 따르는 확률분포
(성공-_특정 사건 발행 = p, 실패_ 특정 사건 발행 X = q= 1-p)
P(X=0) = q, P(X=1)= p, 0 <= p <= 1, q= 1-p
- 모수가 하나이며 서로 반복되는 사건이 일어나는 실험의 반복적 실행을 확률분포로 나타낸 것
기댓값: E(x) =p, 분산: V(x) = p(1-p), x= {0.1}
이항분포 (독립된 베르누이 시행을 여러 번 한 경우)
(이항분포 = 한 번의 시행에서 사건 A가 일어날 확률을 p, 일어나지 않을 확률을 q라고 할 때, n 번의 독립시행에서 사건 A가 일어나는 횟수를 X라고 하면 확률변수 X의 확률분포는 다음과 같다)
- 서로 독립된 '베르누이 시행을 n 회 반복할 때' 성공한 횟수를 x라 하면, '성공한 x의 확률분포를 말함'
- 확률변수가 K가 n, p 두 개의 모수를 가며, K~B(n,p) 로 표기함
- n=1 일 때, 이항분포가 베르누이분포임
- 이항분포의 기댓값: E(x) = np
- 이항분포의 분산: V(x) = np(1-p)
예) 자유튜 성공률이 80% 인 '농구선수' 가 10번의 자유투를 했을 때 성공횟수를 X라 하고, X라는 횟수만큼 성공할 확률 P(x)
1) 제품을 검사 시, 정상품과 불량품을 구분하는 경우
2) 찬성과 반대를 묻는 경우
기하분포
- 베르누이 시행에서 처음 성공까지 시도한 횟수 x를 확률변수로 가지는 분포, 지지집합(x) = {1,2,3,..}
- 성공확률 p 인 베르누이 시행에 대해, x번 시행 후 첫 번째 성공을 얻을 확률, X~ G(p) 로 표기
연속형 확률분포
정규분포 = 평균
- 가우스 분포라고도 하며, 수집된 자료의 분포를 근사하는 데 자주 사용함
- 평균과 표준편차에 대해 모양이 결정되고, N(u, o^2) 로 표기함
- 평균 0, 표준편차/ 분산 1인 정규 분포, N(0,1)를 표준 정규 분포, z 분포라고 함
- 예) 키, 몸무게, 시험 점수 등 거의 대부분의 측정값이 정규분포를 따름
- 정규분포의 평균 주위로 표준편차의 1배 범위에 있을 확률 68%, 2배 범위 안 95%, 3배 범위 안 99.7% (정규분포의 3시그마 규칙)
[정규분포의 3 시그마 규칙]
- 약 68%의 값들이 평균에서 양쪽으로 1 표준편차 범위에 존재
- 약 95%의 값들이 평균에서 양쪽으로 2 표준편차 범위에 존재
- 거의 모든 값들 (실제로는 99.7%)이 평균에서 양쪽으로 3 표준편차 범위에 존재
-> 대부분의 측정값을 정규분포로 가정하는 이유 "정규분포의 당위성"
- 이항분포의 근사
= 시행횟수 N 이 커질 때, 이항분포 B(N, p)는 평균 Np, 분산 Npq인 정규분포와 N (Np, Npq)와 거의 같아짐
- 중심극한 정리
= 표본의 크기가 N인 확률표본의 '표본평균'은 N이 충분히 크면 근사적으로 정규분포를 따르게 됨/
= 모집단의 분포와 상관없이 표본의 크기가 30 이상이 되면 N이 커짐에 따라 표본평균의 분포가 정규분포에 근사해 짐
- 오차의 법칙
= 실제 값의 MLE가 측정값의 평균이라면, 오차는 정규분포를 따름
= MLE (Maxium Likelihood Estimator) : 실제 값일 가능성이 가장 높은 값
= 오차 (error): e = x - u
t 분포 [평균]
- 정규분포는 표본의 수가 적으면 신뢰도가 낮아짐 (n이 30개 미만인 경우)
- 표본이 적은 경우 예측 범위가 넓은 t- 분포를 사용함
- t- 분포는 표본의 개수에 따라 그래프의 모양이 변함
-> 표본의 개수가 많아질수록 정규분포와 비슷하며, 적을수록 옆으로 퍼짐
-> 표본의 개수가 적을수록 신뢰도가 낮아지기 때문에 예측 범위를 넓히기 위해 옆으로 퍼지게 됨
- 그래프의 x축 좌표를 t값이라 부르며, t분포표를 사용해 구하고 검정에 사용함
x ^2 분포 [한 개 분산]
- 분산의 특징을 확률분포로 만든 것으로, 카이 (x)는 평균 0, 분산 1인 표준정규분포를 의미함
- 0 이상의 값만 가질 수 있으며, 오른쪽 꼬리가 긴 비대칭 모양
- 표본의 수가 많아지면 옆으로 넓적한 정규분포 형태가 됨
F-분포 [두 개 분산]
- 카이제곱분포와 같이 분산을 다룰 때 사용하는 분포
- 카이제곱과 비슷하게 비대칭 모양이며, 양수만 존재, 표본의 수가 많아지면 1을 중심으로 정규분포 모양이 됨
- 카이제곱분포는 한 집단의 분산, F분포는 두 집단의 분산이 크기가 서로 같은지 또는 다른지 비교하는 데 사용함
- 두 집단의 분산을 나누었을 때 1이면 두 집단의 크기가 같음으로 판단
- F 검정과 분산분석 (ANOVA) 에서 사용됨
연속균등분포
- 연속확률분포로 분포가 특정 범위 내에서 균등하게 나타나 있을 경우
- 두 개의 매개변수 a, b를 받으며, [a,b] 범위에서 균등한 확률을 가짐
- u(a,b)로 나타내며, u(0,1)인 경우 '표준연속균등분포'라고 함
지수분포
- 사건이 서로 독립적일 때, 다음 사건이 일어날 때까지 대기 시간은 지수분포를 따름
- [참고] 일정 시간 동안 발생하는 사건의 횟수는 포아송 분포를 따름
- 지수분포와 포아송은 람다(ㅅ) 를 사용함 -> ㅅ: 정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기댓값
WHEN
- z 분포, t 분포= 한 집단 또는 두 집단의 평균이 같은지를 검정
- x^2 분포= 한 집단의 모분산 검정 (모수), 범주형 변수의 적합도, 동질성, 독립성 검정 (비모수)
- F 분포: 두 집단의 분산이 같은지를 검정
통계적 추론의 분류
추론 목적에 따른 통계적 추론의 분류
- 추정 = Estimation, 통계량을 사용하여 모집단의 모수를 구체적으로 추측하는 과정
-> 점추정_Point estimation = 하나의 값으로 모수의 값이 얼마인지 추측함
- 통계량 하나를 구하고 그것을 가지고 모수를 추정하는 방법 - '모수가 특정한 값일 것' 이라고 추정하는 것 (예, A과목 수강 전체 학생 중 50명을 뽑아 조사한 결과 기말 점수가 80점 이었다면, 50명 뿐 아니라 나머지 A과목을 수강한 학생들의 점수도 80점 정도로 추정함)
[점추정량 구하는 법] - 적률법, 최대가능도추정법 (최대우도법), 최소제곱법이 있음 -
-> 구간 측정_ Interval estimation = 모수를 포함할 것으로 기대되는 구간을 확률적으로 구함
- 가설검정_Testing hypothesis = 모수에 대한 가설을 세우고 그 가설의 옳고 그름을 확률적으로 판정하는 방법론
모집단에 대한 특정 분포 가정 여부에 따른 통계적 추론의 분류
- 모수적 추론_Parametric Inference = 모집단에 특정 분포를 가정하고 모수에 대해 추론함
- 비모수적 추론_Non- parametric Inference = 모집단에 대해 특정 분포 가정을 하지 않음