
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 머신러닝
- WISET
- 티스토리챌린지
- 데이터분석
- 연속확률분포
- r #데이터분석 #adsp #자격증 #대외활동 #여름방학 #취업준비
- 기술통계
- R
- 오블완
- 절사평균
- ADSP
- 대학생
- 이항분포
- 평균
- 옻
- 자격증
- 인스타툰 #지식 #클래스101 #전자책 #인스타그램 #인스타 #만화 #웹툰 #아이패드드로잉
- dsa프로젝트
- 3ㅣ
- 데이터분석프로젝트
- 신청
- 데이터독학
- 파이썬
- 분위수
- 방학
- 3과목
- 정기시험
- 베르누이
- 독학
- 기하분포
- Today
- Total
mmings_pring_day
[머신러닝] 타이타닉 본문
1. 데이터 불러오기
import numpy as np
import pandas as pddf= pd.read_csv('data/train.csv')
df.head(3)
2. 데이터프레임 변환하기
(1) DataFrame 에서 새로운 column 생성 및 수정
1. Passenger Class(Pclass) 별로 생존 비율을 구하시오.
-> 각 passenger class 별로 총 탑승객의 수를 구하고, 생존한 탑승객의 수를 구한 뒤 (생존한 탑승객 수)/ (총 탑승객 수)를 passenger class 별로 계산하면 됨
df['survival_rate_per_class'] = df['Pclass_per_Survived']/ df['Pclass_per_Passenger']
print(df['survival_rate_per_class'].dropna())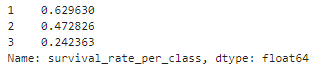
2. 나이가 10살 미만 (Age <10) 인 승객들 중 생존 비율을 구하시오.
또한, 10살 이상 (Age >= 10) 의 승객들 중 생존 비율을 구하시오.
cond1 = (df['Age'] < 10) # 10살 미만
cond2 = (df['Age'] >= 10) # 10살 이상
under10_ratio = df[cond1]['Survived'].mean()
over10_ratio= df[cond2]['Survived'].mean()
# 결과 출력
print(f"10살 미만 승객의 survival ratio: {under10_ratio:.4f}")
print(f"10살 이상 승객의 survival ratio: {over10_ratio:.4f}")
# 조건: 나이가 10살 미만이면서 생존한 승객
cond1 = (df['Age'] < 10) & (df['Survived'] == 1)
# 해당 조건에 맞는 'Survived' 열 선택
df_under_10_survived = df.loc[cond1, 'Survived']
# 생존 비율 계산 (1의 값만 남기므로 생존 비율은 1)
survival_rate_under_10 = df_under_10_survived.mean()
print(f"10살 미만 생존자 중 생존율: {survival_rate_under_10 * 100:.2f}%")
-> loc을 사용할 때는 [조건, 열] 형태로 사용해야 합니다. df[cond1].loc[...] 방식보다는 df.loc[...]를 사용하는 것이 정확합니다.
-> 조건이 '나이가 10살 미만'이면서 '생존한 (Survived=1)' 인 승객을 구할 때 'df.loc[cond1, 'Survived'] 하는 거 기억하기!
* 이 부분을 더 풀어서 설명하면 *
1) 조건 필터링
cond1 = (df['Age'] < 10)
df_under_10 = df[cond1] # cond1에 맞는 데이터프레임을 필터링
2) 필터링한 데이터에서 특정 열만 선택하기
df_under_10_survived = df_under_10['Survived'] # 생존 여부 열만 가져오기
-> 이 두 과정을 하나로 합치면 '.loc' 이용하기
df_under_10_survived = df.loc[cond1, 'Survived']
3. 생존 비율 계산하기
'Survived' 열은 1(생존), 0(사망)으로 되어 있기 때문에, 이 값들의 평균을 구하면 생존 비율이 됩니다. 따라서 mean()을 사용하면 생존 비율을 구할 수 있음
survival_rate_under_10 = df_under_10_survived.mean()
코드 흐름 기억하기:
✅조건을 먼저 만든다.데이터 필터링 (df[cond1] 또는 df.loc[cond1, 'Survived']).
✅필터링한 데이터의 평균을 구한다 (.mean()).
# 조건: 나이가 10살 이상이면서 생존한 승객
cond2 = (df['Age'] >= 10) & (df['Survived'] == 1)
# 해당 조건에 맞는 'Survived' 열 선택
df_over_10_survived = df.loc[cond2, 'Survived']
# 생존 비율 계산
survival_rate_over_10 = df_over_10_survived.mean()
print(f"10살 이상 생존자 중 생존율: {survival_rate_over_10 * 100:.2f}%")3. 아래 df.info()를 실행한 결과를 보면 Age column에서 714개의 row만 값이 채워져 있고, 나머지 row에는 값이 비어 있는 것을 알 수 있다. 지금부터 Age 변수의 값이 비어져 있는 row들은 버리고, 나머지 row들만 변수 df에 들어있도록 코드를 실행하자.
1) df.info()

2) df['Age'].isnull(). sum() -> 177
3) df.dropna()
df['Age']= df['Age'].dropna()
df= df.reset_index(drop= True)
df

df['Age'].isnull().sum()
4. 다음과 같은 조건을 만족하는 함수 'get_age_group(x)' 를 작성하시오.
✅ for 문 (반복문, 주어진 범위나 리스트, 배열 같은 데이터를 반복해서 처리할 때 사용)
-> for i in range() =
for 변수 in 반복할_범위:
print (i) -> 반복할 코드
* 'i'라는 변수를 미리 선언할 필요 없음/ for 문은 i 라는 변수를 자동으로 선언하고 값을 할당해 줌*
fruits = ['apple', 'banana', 'cherry']
for fruit in fruits:
print(fruit)✅ if 문 (조건문, 주어진 조건이 참일 때만 특정 코드를 실행하게 함)
if 조건: (# 조건이 참일 때 실행할 코드)
* 변수를 미리 선언해야 함/ if 문에서 사용하는 변수는 조건문이 실행되기 전에 값을 가지고 있어야 함*
age= 18
if age >= 18:
print("성인입니다.")
else:
print("미성년자입니다.")
✅ while문 (while 문, 주어진 조건이 참인 동안 계속해서 코드를 반복 실행하는 반복문, 조건이 거짓이 되면 루프를 종료함)
whiile 조건: (# 조건이 참일 때 반복할 코드)
* while 문도 변수를 미리 선언해야 함/ while 문은 변수가 조건에 벗어날 때까지 계속 실행됨 (루프가 한 번 실행될 때마다 변수는 1씩 증가하고, 결국 변수가 5가 되면 루프가 종료됨) *
count = 0
while count < 5:
print(count)
count += 1
for i in range(10):
if i % 2 == 0:
print(f"{i}는 짝수입니다.")
else:
print(f"{i}는 홀수입니다.")
1) def 로 함수 선언하기
def 함수이름 (매개변수1, 매개변수2, ...):
# 함수 내부에서 실행할 코드
return 반환값 # 반환할 값이 없으면 생략 가능def say_hello(name):
# 'name'이라는 매개변수를 받아서, 'name'을 포함한 인사를 출력함
print(f"안녕하세요, {name}님")
# 함수를 호출할 때는 'say_hello('철수')'처럼 사용가능
2-1) 함수 안에서 'for'문 사용하기: 문자열 리스트를 처리하는 함수
def choose_color(colors): #colors 는 매개변수
for color in range(colors):
print(f"선택한 색상: {color}")- 함수 호출
colors= (['red', 'blue', 'green'])
choose_colors(colors)- 출력
선택한 색상: red
선택한 색상: blue
선택한 색상: green
2-2) 함수 안에서 'for'문 사용하기: 숫자 리스트를 처리하는 함수
def sum_numbers(numbers):
total= 0
for number in numbers:
total += number
return total- 함수 호출
sum_numbers([1,2,3,4])- 출력
결과: 10
def get_age_group(x):
if x < 10:
print('group1')
elif 10 <= x <30:
print('group2')
elif 30 <= x <50:
print('group3')
else:
print('group4')get_age_group(10,5)
5. 위에서 작성한 함수를 활용하여 age를 그룹화한 column인 age_group column을 생성하시오.
def get_age_group(x):
print(f"Input value: {x}") # x 값을 출력
if x < 10:
return 'group1'
elif 10 <= x < 30:
return 'group2'
elif 30 <= x < 50:
return 'group3'
else:
return 'group4'* print()는 오류를 직접적으로 고치지 않지만, 오류의 원인을 찾을 수 있게 도와줍니다. 디버깅을 위해 print()를 사용한 예 *
- df['Age']에 값이 정상적으로 들어가 있는지 확인합니다.
- get_age_group() 함수에서 조건이 맞지 않으면 반환하지 않도록 되어 있는 경우는 없는지 봅니다.
df['age_group'] = df['Age'].apply(get_age_group)
df['age_group']
6. age_group별로 각 그룹에 해당하는 인원수와 평균 Fare를 구하세요.
# age_group별 인원수 구하기
count = df.groupby('age_group').agg('count') #혹은 count()
# 결과 확인
print(count)
avg_fare= df.groupby('age_group')['Fare'].agg('mean')
avg_fare
- groupby( ) 구조식
df.groupby(['column1', 'column2', ...])['target_column'].agg(function)
1) df. groupby( ): 데이터를 그룹화함
2) ['column1', 'column2',...] : 그룹화에 사용할 칼럼(또는 칼럼들)을 지정함
-> 여러 개의 칼럼 지정: df.groupby(['column1', 'column2',..'])
-> 하나의 칼럼 지정: df.groupby('column')
3) ['target_column']: 그룹화 후 집계를 할 대상 칼럼을 지정함
4) .agg(function): 집계 함수로, 평균('mean'), 합계('sum'),최댓값('max'),최소값('min'),인원수('count') 등 다양한 함수 이용 가능
df.groupby('age_group')['Fare'].agg('mean')
* count( ): 각 그룹에 속한 데이터의 개수를 세는 함수/ 그룹화된 데이터에서 그룹별로 몇 개의 데이터가 있는지 계산 *
df.groupby(['column1', 'column2', ...]).count()df.groupby('age_group').count() #age_group별로 몇 명이 속해 있는지 계산
*여러 집계 함수 사용*
df.groupby('group_column').agg({'target_column1': 'mean', 'target_column2': 'sum'})
- groupby( ) 와 pivot_table( ) 비교
1) groupby( ): 데이터프레임을 하나 이상의 컬럼을 기준으로 그룹화하여 집계할 때 사용
-> 그룹별로 집계 함수를 적용
df.groupby(['column1', 'column2'])['target_column'].agg('mean')
2) pivot_table( ) : 데이터를 피벗 테이블 형태로 변환하여 여러 집계 함수와 다양한 집계 옵션을 지원
-> 데이터를 행, 열, 값으로 나누어 집계할 수 있으며, 여러 집계 함수와 필터를 동시에 사용 가능
df.pivot_table(
values='target_column', #values: 집계할 데이터 컬럼 지정
index='row_index_column', #index: 결과의 행 인덱스가 될 칼럼 지정
columns='column_index_column', #column: 결과의 열 인덱스가 될 칼럼 지정
aggfunc='mean' #aggfunc: 집계 함수를 지정
)# pivot_table 사용
pivot_table_result = df.pivot_table(values='Fare',index='age_group', aggfunc='mean')
#그룹별 평균 요금 계산'2024-2학기 > 머신러닝' 카테고리의 다른 글
| [머신러닝] (1) | 2024.11.10 |
|---|---|
| [머신러닝] California Housing dataset (week03- pracitce) (0) | 2024.09.19 |

