
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 독학
- 3과목
- 정기시험
- 방학
- 평균
- r #데이터분석 #adsp #자격증 #대외활동 #여름방학 #취업준비
- 기술통계
- 자격증
- 데이터분석
- dsa프로젝트
- 옻
- 기하분포
- 3ㅣ
- 데이터독학
- 절사평균
- 신청
- 베르누이
- 인스타툰 #지식 #클래스101 #전자책 #인스타그램 #인스타 #만화 #웹툰 #아이패드드로잉
- 대학생
- 연속확률분포
- R
- ADSP
- 이항분포
- 오블완
- 머신러닝
- 분위수
- 티스토리챌린지
- 데이터분석프로젝트
- WISET
- 파이썬
- Today
- Total
mmings_pring_day
[머신러닝] California Housing dataset (week03- pracitce) 본문

# 목적
-> 캘리포니아 인구조사 데이터를 사용해 캘리포니아 주택 가격 모델 만들기
-> 학습시킨 모델에 다른 측정 데이터가 주어졌을 때 구역의 중간 주택 가격을 예측해야 함 -> 지도학습 중 '회귀'
1단계: 문제 정의
[회귀분석의 종류]- 단변량 회귀: 하나의 특성을 기반으로 예측- 다변량 회귀: 여러 개의 특성을 기반으로 예측 (이 데이터셋은 '구역의 인구, 중간 소득 등 feature가 많으므로 다변량 회귀)
2단계: 성능 측정 지표 선택
-> 회귀 분석의 대표적인 성능 측정 지표는 '평균 제곱근 오차 (RMSE; Root Mean Square Error)'


: 시스템이 하나의 샘플 데이터 x^(i) 를 받으면 예측 함수에 대입되어 예측 값이 출력됨. RMSE 가 회귀 문제에서 주로 선호되는 성능 측정 지표이지만 경우에 따라 이상치가 많은 구역이 있다면 평균 절대 오차 (Mean Absolute Error)를 고려할 수 있음

1. 데이터 불러오기
import numpy as np
import pandas as pddf = pd.read_csv('data/housing/housing.csv')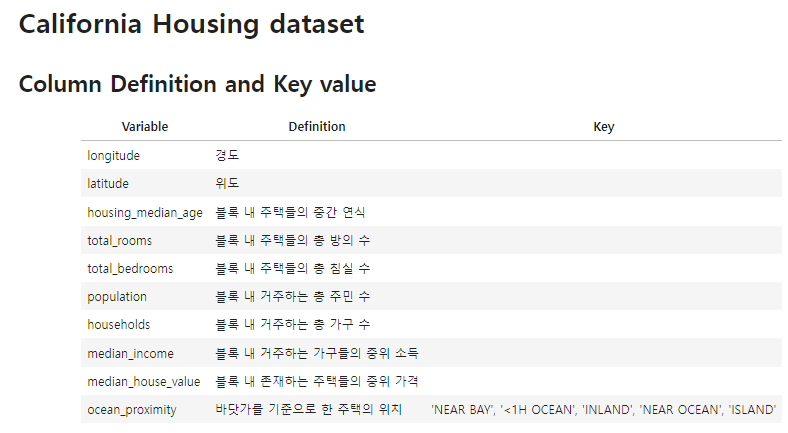
1) df.info( )

(1) 마지막 행인 'ocean_proximity' 만 obect 형이고, 나머지는 모두 float 형
(2) total_bedrooms 행이 결측치를 가지고 있음
2) 각 변수들의 속성에 맞게 데이터 확인 (범주형 변수, 수치형 변수)
- 'ocean_proximity' 속성의 value 값 확인
df['ocean_proximity'].value_counts()
- 수치형 변수들에 대해서 데이터 요약 정보 확인 = df.describe( )
df.describe()
2. 데이터 시각화 (히스토그램으로 데이터 형태 파악하기- 수치형 변수)
df.hist(bins=50, figsize=(20,15))
[이 시각화를 통해서 알 수 있는 정보]
- 중간 소득 (median_income)이 달러 단위가 아님
- 'median-income' 에 대해서, 실제 income 이 아님 (개인정보 문제 때문에) -> 인지해야 함!
데이터 취합시 normalize과정을 수행함 (최소값(0.5), 최대값(15)을 기준으로 실제 데이터를 변환))

- 중간 주택 연도 ('housing median age')와 중간 주택 가격 ('median house value')의 그래프의 오른쪽이 심하게 높아진 것으로 보아, 마지막 값으로 한정시킨 것 같음 (= 모델의 예측 값이 500000을 넘어가지 않도록 했음)
-> 중간 주택 가격 ('median house value')의 특성은 예측하는데 레이블로 사용되기 때문에 '데이터 처리'를 해야 함!!


만약 정확한 가격을 예측할 필요가 있다면, 다음 중 하나의 조치를 취해야 함
- 정확한 y값을 얻을 것
- 학습(train), 평가(test) 데이터셋에서 중간 주택 가격이 500000이상의 데이터는 제거할 것 (일반적)
- 대부분 변수가 'skew'되어 있음 (정규분포 X _머신러닝 알고리즘에서 패턴을 찾기 어려움-> 전처리 필요성)

3. 데이터 간 상관성 살펴보기
[지리적 데이터 시각화]
- x를 경도(longitude), y를 위도(latitude)로 해서 scatterplot 그리기
df.plot(kind='scatter', x='longitude', y='latitude', figsize=(7,7))
- alpha 옵션에 값을 0.1로 줘서 데이터 포인트가 밀집된 영역을 더 잘보이도록 하기
df.plot(kind='scatter', x='longitude', y='latitude', alpha=0.1, figsize=(7,7))
- 원의 크기로 인구 수를, 색상으로 주택 가격대를 나타내는 scatter plot 그리기
df.plot(kind='scatter', x='longitude', y='latitude', alpha=o,4,
s= df['population']/100, label='population', figsize=(10,7),
c= 'median_house_value', cmap=plt.get_cmap('jet'),colorbar=True,
sharex= False)
(원의 반지름은 인구를 나타내고, 색깔은 가격을 나타냄/ 자세히 보면 바다 근처가 집 가격이 더 크다는 것을 알아낼 수 있음
* 물론 바다 근처인데도 불구하고 가격이 높지 않은 지역이 있어서 정보 사용이 간단하지는 않아 보임 *)
-> 주택 가격은 바다와의 인접성과 인구 수에 밀접한 관계가 있어 보임
3-2. 데이터 간 상관성 살펴보기 (변수 별 상관 관계도)
1) 상관관계 조사 (수치형 변수만을 가지고)
corr_matrix= df1.corr()
corr_matrix['median_house_value'].sort_values(ascending= False)
: 상관관계를 보면, 중간 주택 가격(median_house_value)은 중간 소득 (median_income)과 양의 상관관계를 가지며 중간 소득이 올라갈 때 증가함. 위도(latitude)와는 음의 상관관계로 위도가 올라갈 수록 가격이 서서히 내려간다고 볼 수 있음 (*0에 가까운 것은 관계가 없다는 뜻 *)
-> 상관계수는 선형적인 관계만 측정 가능함/ 비선형은 측정 불가
-> 상관계수는 기울기와 관계 없음
2) 중간 주택 가격과 중간 소득을 산점도 (scatter)로 나타내기
from pandas.plotting import scatter_matrixattrs = ['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']
scatter_matrix(df[attrs], figsize=(12,10))
['median house value'와 다른 변수 간의 상관성/ 관계성]
df.plot(kind='scatter', x='median_income', y='median_house_value', alpha= 0.1)

- 주택 가격 (median_house_value)는 중위 소득 (median_income)과 선형적인 관계가 존재!
(이 산점도를 통해 '갈수록 증가하는 상향관계'임을 알 수 있음_ 퍼져있지 않고 몰려있어서 아주 좋은 특성을 가지고 있음.
하지만 $500,000 에서 제한값으로 수평선으로 보이고, $350,000 과 $280,000, $230,000 등 수평선이 보임 -> 이러한 데이터는 좋지 않으므로 삭제 필요)
4. 데이터 전처리
[전처리 방법]
1) 비정상 데이터 제거
- 비정상적인 '중간 주택 가격 (median_house_value)' > = 500000, '중간 주택 연식 (housing_median_age)' >= 50 인 부분 제거
df= df[(df['housing_median_age'] < 50) &
(df['median_house_value'] < 500000)].reset_inces(drop=True)2) train-test split
- 머신러닝 모델을 구축할 때, 학습(train)과 평가(test)를 위한 dataset 을 반드시 나눠야 함
df.info()
from sklearn.model_selection import train_test_split#df_train) 학습 데이터
#df_test) 평가 데이터
df_train, df_test= train_test_split(df, test_size=0.2) #학습용 80%, 평가용 20%로 분리
#train_test_split(*arrays,test_size=None,train_size=None,random_state=None,)
print(df_train.shape, df_test.shape, df.shape)- 본격적인 전처리 전에 특성에 따라 column 들을 다음과 같이 분리하겠음 (column 을 특성에 따라 구분하기)
all_cols= [x for x in df.columns] #모든 형태를 리스트화
geo_cols= ['longitude', 'latitude'] #지리적 특성 column
y_cols= ['median_house_value'] #종속 변수(y)_주택 가격 column
cat_cols= ['ocean_proximity'] #범주형 독립 변수(x) column
num_cols= [x for in all_cols if x not in geo_cols + y_cols + cat_cols] #수치형 독립 변수(x) columnprint(all_cols)
print(geo_cols)
print(y_cols)
print(cat_cols)
print(num_cols)
[결측치 처리 방법 - total_bedrooms 변수에 대해서]
- Feature 삭제하기: drop( )
- 다른 값으로 변경하기 (0 or 평균 or 중간값): fillna( )
df_train.info()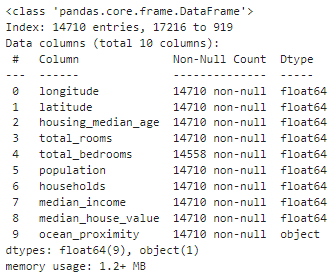
df_test.info()
1) 결측치 제거하기
df_train_removed= df_train[df_train['total_bedrooms'].isnull() == False].reset_index(drop=True)
df_test_removed= df_test[df_test['total_bedrooms'].isnull() == False].reset_index(drop=True)
#결측치 제거 전 데이터 수
print(f"결측치 제거 전:train data 수={df_train.shape[0]}, test data 수={df_test.shape[0]}")
# 결측치 제거 후 데이터 수
print(f"결측치 제거 후: train data 수={df_train_removed.shape[0]}, test data 수={df_test_removed.shape[0]}")
2) 결측치 대체하기
- 데이터를 대체하기 위해선 중간값(median)으로 채워 넣기
-> 범주형 데이터에 대해선 ('ocean_proximity') 중간값이라는 개념이 없음
-> 수치형(numerical), 범주형 데이터로 나누고, 수치형 데이터만 채워넣도록 하겠음
all_cols = df_trn.columns
df_trn_num = df_trn[num_cols] # 학습 데이터 중, 수치형 변수만
df_trn_cat = df_trn[cat_cols] # 학습 데이터 중, 범주형 변수만
df_trn_geo = df_trn[geo_cols] # 학습 데이터 중, 지리적 특성 관련 변수만
df_trn_y = df_trn[y_cols] # 학습 데이터 중, 종속 변수만
df_tst_num = df_tst[num_cols] # 시험 데이터 중, 수치형 변수만
df_tst_cat = df_tst[cat_cols] # 시험 데이터 중, 범주형 변수만
df_tst_geo = df_tst[geo_cols] # 시험 데이터 중, 지리적 특성 관련 변수만
df_tst_y = df_tst[y_cols] # 시험 데이터 중, 종속 변수만
- train data 에서 각 column 별로 어떤 값으로 결측치를 채워 넣을지 결정
from sklearn.impute import SimpleImputer #SimpleImputer= 결측치 채워넣기 가능imputer = SimpleImputer(strategy='median')
imputer.fit(df_train_num) #각각의 변수들의 결측치에 어떤 값으로 채워넣을 지 계산됨
print(imputer.statistics_) # 각 column마다 이 값으로 결측치가 채워짐. 3번째에 해당하는 값이 total_bedrooms column의 빈칸 채우는 값(채워넣을 준비가 됨)
- 어떤 값으로 채워지지? 각 열마다 어떤 값으로 채워지는 지 계산 -> total_bedrooms 의 경우 채워지는 값은 '443'

- train data 를 impute 한 결과 산출
# df_trn_num의 결측치를 impute한 결과(단, numpy array 형태)
X_trn_num = imputer.transform(df_train_num)X_trn_num #array가 반환됨
- 변환된 결과물이 pandas 형태가 되도록
imputer = SimpleImputer(strategy='median').set_output(transform='pandas')
imputer.fit(df_train_num)
print(imputer.statistics_) # 각 column마다 이 값으로 결측치가 채워짐. 5번째 값이 total_bedrooms column의 빈칸 채우는 값
X_trn_num = imputer.transform(df_train_num)
X_trn_num.head()
X_tst_num = imputer.transform(df_test_num)
X_tst_num.head()
* test data 에 채워넣는 값과 train data에서 채워넣는 값은 동일! / 하지만, test data에 값을 채워넣는 과정에 fit( )은 적용하면 안 됨!1 *
imputer = SimpleImputer(strategy='median')
imputer.fit(df_train_num) #각각의 변수들의 결측치에 어떤 값으로 채워넣을 지 계산됨 (X)
print(imputer.statistics_) # 각 column마다 이 값으로 결측치가 채워짐. 3번째에 해당하는 값이 total_bedrooms column의 빈칸 채우는 값
3) 새로운 변수 생성하기
- 주택 가격은 전체 방 개수, 침실 개수보다 '침실 비율 = (침실 개수) / (전체 방 개수)' 에 더 많은 영향이 있음
-> 새로운 유도 변수를 생성 (* 새로운 변수를 유도할 때 사용한 변수는 제거해야 함 *)
X_trn_num.head()
- '결측치 처리'가 완료된 데이터를 활용하여 'bedrooms_per_room' 변수 생성
X_trn_num['bedrooms_per_room']= X_trn_num['total_bedrooms']/ X_trn_num['total_rooms']
X_tst_num['bedrooms_per_room']= X_tst_num['total_bedrooms']/ X_tst_num['total_rooms']-> 'bedrooms_per_room' 을 산출하는데 사용한 'total_bedrooms', 'total_rooms' 는 (기존 것) 제거!!
X_trn_num= X_trn_num.drop(['total_bedrooms', 'total_rooms'], axis=1)
X_tst_num= X_tst_num.drop(['total_bedrooms', 'total_rooms'], axis=1)X_trn_num.head()
4) 수치형 변수 스케일링
- 표준화 혹은 정규화 사용하기 (정규분포로 만들기 위해서)
-> MinMaxScaler = 최소, 최대 맞추기/ StandardScaler= z값으로 정규화 ? (둘 중 하나 사용)
-> scikit-learn 에서는 train, test set 에서 같은 스케일로 데이터를 변환하도록 하는 기능을 제공함.
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler- 각 column 별로 standardize(normalize)하는 방식: MinMaxScaler 사용하기 (변환!)
# scaler = StandardScaler().set_output(transform='pandas')
scaler = MinMaxScaler().set_output(transform='pandas')
scaler.fit(X_trn_num)
- train data를 normalize (스케일링)한 결과 산출
X_trn_num_scaled = scaler.transform(X_trn_num)

* test 데이터에서는 별도로 fit( ) 적용 X, train 데이터에서 사용한 공식은 그대로 사용하기!! *
X_tst_num_scaled = scaler.transform(X_tst_num)
5) 범주형 변수 처리- OneHot Encoder 를 통해 벡터로 변환
-> 범주형 변수를 그대로 사용하지 못하는 경우, 'numerical vector'형태로 형태 변화 필요 (onehot encoding 방법_가장 기본적)

-> 차원을 늘림 (color_red/ color_blue/ color_green)




- train data에서 'ocean_proximity' column 을 onehot encoding 하는 과정
from sklearn.preprocessing import OneHotEncoderencoder = OneHotEncoder(sparse_output= False).set_output(transform='pandas') #불러오기
encoder.fit(df_trn_cat) #준비-> OneHotEncoder(sparse_output= False)
: onehot encoding 결과물은 CSR 형식 -> 익숙한 numpy.ndarray 형식으로 값을 반환
-> set_output(transform= 'pandas')
: 위의 결과물 형식이 numpy array -> pandas DataFrame 형태의 output 출력!
- train data 에서 'ocean_proximity' column 의 범주 값을 onehot encoding!
X_trn_cat = encoder.transform(df_trn_cat) #실행
X_trn_cat- test data 의 onehot encoding 방식과 train data 에서 onehot encoding 방식은 반드시 동일해야 함!
: train data 를 onehot encoding 한 방식으로 test data 도 onehot encoding 하기
X_tst_cat = encoder.transform(df_tst_cat)
X_trn_cat.head()
6) 수치형 변수, 범주형 변수 전처리한 결과 통합하기
- 수치형 변수 전처리 결과
# train data
X_trn_num_scaled.head()
# test data
X_tst_num_scaled.head()
- 범주형 변수 전처리 결과
# train data
X_trn_cat.head()
# test data
X_tst_cat.head()
- 수치형 변수, 범주형 변수를 전처리한 결과를 기존 데이터 (df_trn_geo, df_trn_y) 와 통합
X_trn = pd.concat((df_trn_geo, df_trn_y, X_trn_num_scaled, X_trn_cat), axis=1)
X_tst = pd.concat((df_tst_geo, df_tst_y, X_tst_num_scaled, X_tst_cat), axis=1)X_trn.head()
X_tst.head()
-
자료출처:
https://www.kaggle.com/datasets/camnugent/california-housing-prices
California Housing Prices
Median house prices for California districts derived from the 1990 census.
www.kaggle.com
https://junsik-hwang.tistory.com/34
캘리포니아 주택 가격 예측 모델 만들기 - (1)
# 목적 캘리포니아 인구조사 데이터를 사용해 캘리포니아 주택 가격 모델 만들기. 학습시킨 모델에 다른 측정 데이터가 주어졌을 때 구역의 중간 주택 가격을 예측해야 함. # 파라미터 설명 total_
junsik-hwang.tistory.com
https://junsik-hwang.tistory.com/36#google_vignette
캘리포니아 주택 가격 예측 모델 만들기 - (2) feat.특성 스케일링
이제 데이터를 만져봐야한다. 첫 번째 : total_bedrooms 에만 특성이 없는 경우들이 있었다. (total_bedrooms 만 20433 이다) housing.info() ----------------------------------------- RangeIndex: 20640 entries, 0 to 20639 Data column
junsik-hwang.tistory.com
https://www.kaggle.com/code/alisultanov/regression-xgboost-optuna
Regression | XGBoost + OPTUNA
Explore and run machine learning code with Kaggle Notebooks | Using data from California Housing Prices
www.kaggle.com
https://psystat.tistory.com/136
python 원핫인코딩은 사이킷런의 OneHotEncoder를 사용하자
pandas.get_dummies 대신 sklearn.preprocessing.OneHotEncoder를 쓰자¶ 1. pandas.get_dummies의 문제점¶ pandas.get_dummies는 train 데이터의 특성을 학습하지 않기 때문에 train 데이터에만 있고 test 데이터에는 없는 카테
psystat.tistory.com
https://eda-ai-lab.tistory.com/655
[Machine Learning Advanced] 8강. 머신러닝 강의 - 캐글에서 활용되는 알아두면 좋은 팁 (Tips)
이번 글에서는 캐글에서 활용되는 알아두면 좋은 몇가지 팁들에 대해 알아보도록 하겠습니다. 먼저, 베이스라인을 만든 이후에 고려하면 좋을 사항들에 대해서 살펴본 이후 마지막 성능을 쥐어
eda-ai-lab.tistory.com
'2024-2학기 > 머신러닝' 카테고리의 다른 글
| [머신러닝] (1) | 2024.11.10 |
|---|---|
| [머신러닝] 타이타닉 (0) | 2024.09.16 |
